Налаштування Fledge
Багато факторів впливатимуть на продуктивність системи Fledge
- Продуктивність центрального процесора, пам’яті та пам’яті основного обладнання
- Продуктивність каналу зв'язку з датчиками
- Комунікації до північних систем
- Вибір системи зберігання
- Зовнішні запити через загальнодоступний REST API
Багато з них знаходяться поза контролем самого Fledge, однак можна налаштувати спосіб використання певних активів Fledge для досягнення кращої продуктивності в межах обмежень середовища розгортання.
Розширена конфігурація Південного Сервіса
Кожен з південних сервісів у Fledge має набір розширених параметрів конфігурації. Дос�туп до них здійснюється шляхом редагування конфігурації самого південного сервіса. З’явиться екран із набором панелей із вкладками, виберіть вкладку з позначкою Advanced Configuration, щоб переглянути та змінити параметри розширеної конфігурації.
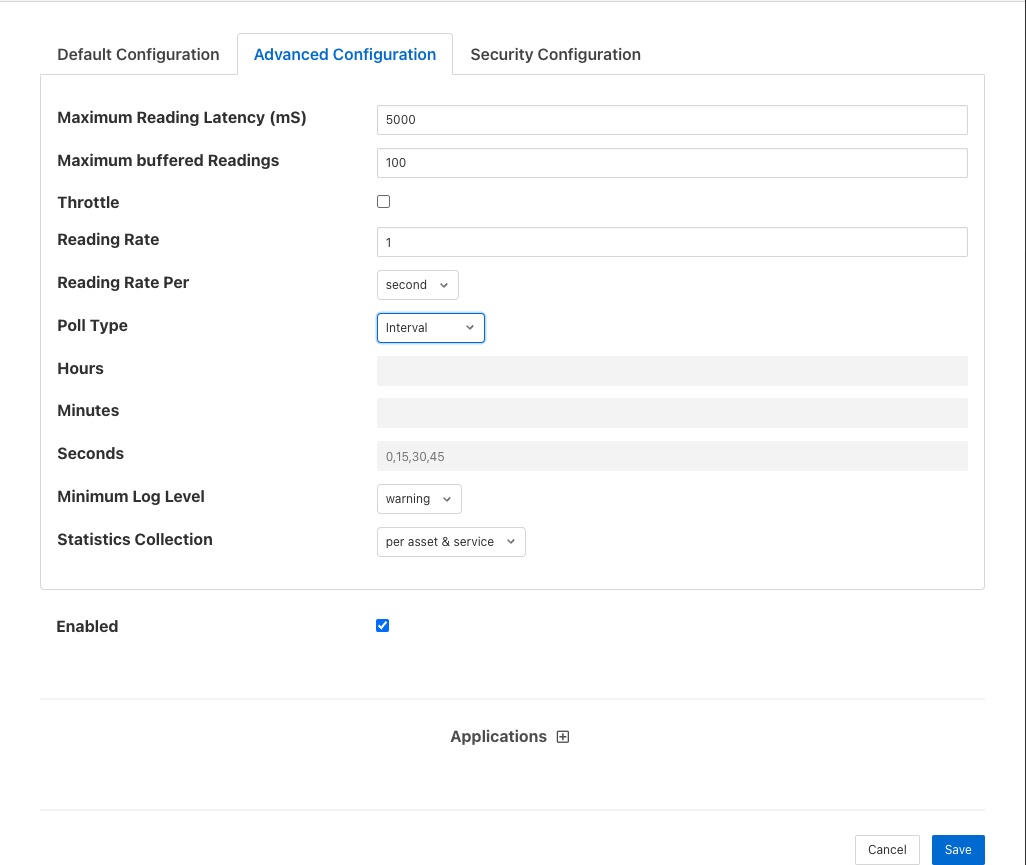
Maximum Reading Latency (mS) - Це максимальний період часу, протягом якого південний сервіс буферизуватиме зчитування перед тим, як надсилати його на рівень зберігання. Значення виражається в мілісекундах і фактично визначає максимальний час очікування, перш ніж ви зможете переглянути дані, отримані цим південним сервісом.
Maximum buffered Readings - Це максимальна кількість зчитувань, які сервіс півдня буде буферизувати перед спробою надіслати ці зчитування далі до сервіса зберігання. Це та налаштування вище працюють разом, щоб визначити стратегію буферизації південного сервіса.
Throttle - Якщо ввімкнено, це дозволяє регулювати швидкість читання південним сервісом. Сервіс намагатиметься опитувати зі швидкістю, визначеною Reading Rate, однак, якщо це неможливо, оскільки показання пересилаються з південного сервіса з нижчою швидкістю, швидкість читання буде зменшено, щоб запобігти буферизацію в південному сервісі від перевантаження.
Reading Rate - Швидкість опитування для цього південного сервіса. Цей параметр діє, лише якщо ваш південний плагін опитується, асинхронні південні сервіси не використовують цей параметр. Одиниці вимірювання визначаються налаштуванням пункту Reading Rate Per.
Asset Tracker Update - Це визначає, як часто засіб відстеження активів очищає кеш інформації відстеження активів на рівень зберігання. Це значення, виражене в мілісекундах. Засіб відстеження активів лише записує оновлення, тому, якщо у вас є фіксований набір активів, що надходять у трубопровід, засіб відстеження активів записуватиме будь-які дані лише під час першого перегляду кожного активу, а потім не виконуватиме подальших записів. Якщо у вас є мінливість у ваших активах або структурі активів, засіб відстеження активів буде більш активним, і стане кориснішим налаштувати цей параметр.
Reading Rate Per - Це визначає одиниці, які �використовуватимуться у значенні Reading Rate. Він дозволяє вибрати за секунду, хвилину чи годину.
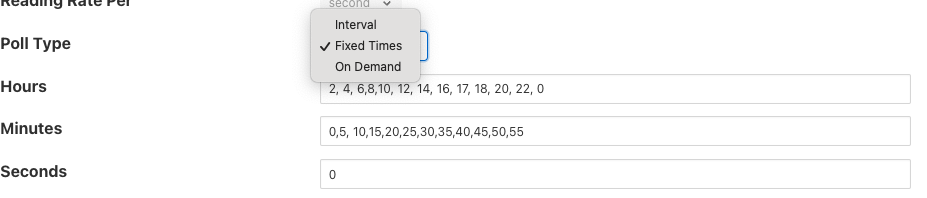
Poll Type - Це визначає механізм, який використовується для керування запитами на опитування, які надсилатимуться до плагіна. Наразі доступні три варіанти: інтервальне опитування, опитування за фіксованим часом і опитування за запитом.
- Interval опитування надсилає запит на опитування з фіксованою швидкістю, яка визначається параметрами Reading Rate і Reading Rate Per, описаними вище. Перший запит на опитування буде видано після запуску плагіна та не буде синхронізовано з будь-яким часом чи іншими подіями в системі.
- Fixed Times опитування надсилає запити на опитування у фіксований час, який визначається набором годин, хвилин і секунд. Цей час визначено в місцевому часовому поясі машини, на якій запущено екземпляр Fledge.
- On Demand опитування не виконуватиме жодного регулярного опитування, натомість воно чекатиме на надсилання контрольної операції до сервіса. Ця операція наз�ивається poll і не приймає аргументів. Це дозволяє ініціювати опитування механізмами керування зі сповіщень, розкладів, північних сервісів або запитів API.
Hours - Це визначає години, коли буде зроблено запит на опитування. Години виражаються за допомогою 24-годинного годинника, із запитами на опитування, лише коли поточна година збігається з однією з годин у списку годин, розділених комами. Якщо поле Години залишити незаповненим, опитування буде видано протягом кожної години дня.
Minutes -Це визначає хвилини дня, коли надходять запити на опитування. Запити на опитування виконуються лише тоді, коли поточна хвилина збігається з однією з хвилин у списку хвилин, розділених комами. Якщо поле Хвилини залишити порожнім, запити на опитування надсилатимуться протягом будь-якої хвилини протягом години.
Seconds - Це визначає секунди, коли будуть зроблені запити на опитування. Секунди — це список секунд, розділених комами, запити на опитування виконуються, коли поточна секунда відповідає одній із секунд у списку. Якщо вибрано опитування Fixed Times, то поле Seconds не має бути порожнім.
Minimum Log Level - Цей параметр конфігурації можна використовувати для встановлення журналів, які відображатимуться для цього сервіса. Він визначає рівень журналювання, який надсилається до системного журналу, і може бути встановлено на помилка, попередження, інформація чи налагодження (error, warning, info чи debug). Журнали вибраного рівня та вищого рівня надсилатимуться до системного журналу. Ви можете отримати доступ до вмісту цих журналів, вибравши значок журналу в нижньому лівому куті цього екрана.
Statistics Collection - Цей параметр конфігурації можна використовувати для контролю того, наскільки докладною є статистика, зібрана південним сервісом. Є три варіанти, які можна вибрати
Параметр per asset & per
serviceзбиратиме одну статистику для кожного отриманого об’єкта та загальну статистику для всього сервіса. Опція perserviceлише збирає загальну статистику прийому послуги, а опція per asset збирає статистику лише для кожного активу, а не для всього сервіса. За замовчуванням статистика збирається на основі активів і послуг. Це не найкращий параметр, якщо велика кількість окремих активів приймається одним південним сервісом. Використання параметрів «за активом» або «за активом і послугою» має бути обмежено південним сервісом, яка збирає відносно невелику кількість окремих активів. Збір великої кількості статистичних даних для 1000 або більше різних активів призведе до значного збільшення продуктивності та може перевантажити менш добре забезпечені екземпляри Fledge. Якщо велика кількість активів поглинається одним південним сервісом, це значення має бути встановлено на perservice.Примітка
Налаштування Statistics Collection не видалить жодну наявну статистику, вона залишиться та буде відображена в історії статистики. Це впливає лише на нові зібрані значення. Рекомендується встановлювати це перед першим запуском сервіса, якщо потрібно, щоб не було записаних статистичних значень для активів або сервіса.
Примітка
Якщо використовується параметр per
service, то на сторінці інтерфейсу користувача, на якій відображаються південні сервіси, не відображатимуться назви активів і їх кількість для кожного з активів, отриманих цим сервісом.
- Performance Counters - Цей параметр дозволяє збирати лічильники продуктивності, які можна використовувати для налаштування південного сервіса.
Лічильники продуктивності
Кілька лічильників продуктивності можна зібрати в південному сервісі, щоб допомогти охарактеризувати продуктивність послуги. Це призначено для надання вхідних даних для налаштування сервіса, і збір цих лічильників не слід залишати ввімкненим під час використання сервіса в робочих умовах.
Лічильники продуктивності збираються в сервісі, а звіт записується раз на хвилину на рівень зберігання для подальшого отримання. Записані значення є
- Мінімальне значення лічильника, що спостерігається протягом поточної хвилини
- Максимальне значення лічильника, що спостерігається протягом поточної хвилини
- Середнє значення лічильника, що спостерігається протягом поточної хвилини
- Кількість зразків лічильника, зібраних протягом поточної хвилини
У поточному випуску лічильники продуктивності можна отримати лише шляхом прямого доступу до бази даних конфігурації та статистики, вони зберігаються в таблиці monitors. Або через REST API. Майбутні випуски включатимуть інструменти для отримання та аналізу цих лічильників продуктивності.
Щоб отримати доступ до лічильників продуктивності через REST API,
використовуйте точку входу /fledge/monitors, щоб отримати всі
лічильники, або /fledge/monitor/{service name}, щоб отримати лічильники
для одного сервіса.
Коли збір увімкнено, для ввімкненого південного сервіса збиратимуться такі лічильники.
| Лічильник | Опис | Причини та заходи щодо усунення |
|---|---|---|
| queueLength | Загальна кількість зчитувань, поставлених у чергу в південному сервісі для надсилання до сервіса зберігання. | Великі черги в південному сервісі означатимуть, що сервіс займатиме більше, ніж зазвичай, але само по собі це не буде проблемою. Однак якщо розмір черги безперервно зростає, зрештою відбудеться збій розподілу пам’яті в південному сервісі. Якщо ввімкнути обмеження швидкості прийому даних, кількість даних, які додаються до черги, може бути достатньою для вирішення проблеми, однак дані збиратимуться зі зниженою швидкістю. Іншим рішенням може бути швидший плагін зберігання, можливо, використання механізму зберігання в пам’яті. Якщо ваш екземпляр має багато південних сервісів, можливо, варто розглянути можливість розділити південні сервіси між кількома екземплярами. |
| ingestCount | Кількість зчитувань, отриманих під час кожної взаємодії плагіна. | Лічильник відображає кількість зчитувань, які повертаються для кожного виклику до точки входу опитування плагіна South або асинхронного виклику плагіна South. Як правило, це число має бути помірно низьким, якщо дуже великі номери повертаються під час одного виклику, це призведе до накопичення дуже великих черг у південному сервісі, а продуктивність системи буде знижена через великий пакет даних, який, можливо, перевантажить інші рівні чергуються з періодами бездіяльності. В ідеалі піки повинні бути усунені, а швидкість залишатися «рівною», щоб найкраще використовувати систему. Подумайте над тим, щоб змінити конфігурацію плагіна півдня так, щоб він повертав менше даних, але частіше. |
| readLatency | Найдовший час, який зчитування перебувало в черзі між поверненням південного модуля та відправленням на рівень зберігання. | Цей лічильник описує, як довго (у мілісекундах) найстаріше зчитування чекає у внутрішній черзі обслуговування півдня перед тим, як буде надіслано на рівень зберігання. Це має бути менше або дорівнювати визначеній максимальній затримці, воно може бути трохи більше, щоб урахувати час керування чергою, але не повинно бути значно вищим. Якщо він значно вищий протягом тривалого часу, це означатиме, що сервіс зберігання не в змозі впоратися з покладеним на неї навантаженням. Можливо, налаштування рівня зберігання, зміна плагіна з вищою продуктивністю або плагіна, який краще підходить для вашого робочого навантаження, може вирішити проблему. Крім того, розгляньте можливість зменшення навантаження, розділивши південні сервіси між кількома примірниками Fledge. |
| flow controlled | Кількість разів, коли швидкість читання була знижена через надмірні черги, що накопичуються в південному сервісі. | Це тісно пов’язане з лічильником queuLength і має майже такий же набір дій, які слід виконувати, якщо послуга часто керується потоком. Зменшення швидкості прийому або додавання фільтрації в трубопровід для зменшення обсягу даних, що передаються далі до сервіса зберігання, може полегшити проблему. Загалом, якщо можна виконати обробку, яка скорочує дані з високою пропускною здатністю до даних з нижчою пропускною здатністю, які все ще можуть характеризувати вміст із високою пропускною здатністю, то це слід робити якомога ближче до джерела даних, щоб зменшити загальне навантаження на систему. |
| throttled rate | Швидкість, з якою дані надходять у результаті регулювання керування потоком. | Цей лічильник більше призначений для отримання інформації про те, яка може бути розумна швидкість прийому, яку система може підтримувати з поточною конфігурацією. Це корисно, оскільки дає гарне уявлення про те, наскільки далека поточна конфігурація системи від бажаної продуктивності. |
| storedReadings | Зчитування успішно надіслано на рівень зберігання. | Цей лічильник показує пропускну здатність, доступну від сервіса до механізму зберігання. Це має бути принаймні таким же високим, як швидкість прийому, якщо дані не збираються накопичуватися в буферах у сховищі. Зміна розширених налаштувань максимальної затримки та максимальних буферизованих зчитувань на південному сервері може вплинути на цю пропускну здатність. |
| resendQueued | Кількість зчитувань у черзі для повторного надсилання. Зауважте, що зчитування можуть бути поставлені в чергу для повторного надсилання кілька разів, якщо повторне надсилання також не вдалося. | Це хороший показник умов перевантаження в системі зберігання даних. Постійно високі значення цього лічильника вказують на необхідність покращення продуктивності рівня зберігання. |
| removedReadings | Кількість зчитувань, які було видалено після занадто багатьох спроб зберегти їх на рівні зберігання. | Зазвичай це значення має бути нульовим або близьким до нуля. Будь-які значні значення тут є вказівкою на критичну помилку або з даними південного плагіна, які створюються, або з роботою рівня зберігання. |
Опитування з фіксованим часом
Опитування з фіксованим часом можна використовувати кількома способами для контролю надходження запитів на опитування, серед можливих скриптів:
- Опитування в фіксований час протягом хвилини або години.
- Опитування лише в певні періоди доби.
Щоб проводити опитування у фіксований звичайний час, просто встановіть час, коли потрібно опитування. Наприклад, щоб опитувати кожні 15 секунд через 0 секунд після хвилини, 15, 30 і 45 секунд після години, просто введіть у поле Seconds значення 0, 15, 30, 45 і залиште хвилини та години порожніми.
Якщо ви бажаєте здійснювати опитування щогодини та кожні 15 хвилин після цього, установіть для поля Хвилини значення 0, 15, 30 і 45, а для поля Секунди встановіть значення 0. Налаштування Секунди на інше одне значення, наприкл�ад 30, просто змінить час опитування на 0 хвилин і 30 секунд, 15 хвилин і 30 секунд і т. д. Якщо задано кілька значень секунд, буде проведено кілька опитувань. Наприклад, якщо для параметра Хвилини встановлено значення 0, 15, 30, 45, а для параметра Секунди встановлено значення 0, 30. Опитування відбуватиметься о 0 хвилинах і 0 секундах, 0 хвилинах і 30 секундах, 15 хвилинах і 0 секундах, 15 хвилин тридцять секунд.
Поле Годин, якщо його не залишити порожнім, працюватиме так само, як хвилини вище.
Інше використання цієї функції полягає в опитуванні лише в певний час доби. Як приклад, якщо ми хочемо проводити опитування кожні 15 хвилин між 8:00 і 17:00, ми можемо встановити для поля Годин значення 8,9,10,11,12,13,14,15,16 і * Хвилини* мають значення 0, 15, 30, 45. Поле секунд можна залишити 0.
Примітка Останнє опитування дня буде о 16:45 у вказаній вище конфігурації.
Незважаючи на те, що інтервали між опитуваннями, показані у наведених вище прикладах, усі однакові, немає жодних вимог, щоб це було так.
Налаштування використання буфера
Налаштування південного сервіса дозволяє контролювати спосіб використання буферизації в південному сервісі. Встановлення низького значення затримки призводить до частих викликів для надсилання даних до сервіса зберігання, а отже означає, що дані стають доступнішими швидше. Однак надсилання невеликої кількості даних під час кожного виклику до системи зберігання не призводить до найоптимальнішого використання комунікацій або самого механізму зберігання. Встановлення вищого значення затримки призводить до надсилання більшої кількості даних за транзакцію із системою зберігання та підвищення ефективності системи. Ціною цього є потреба в більшому обсязі пам’яті в південному сервісі.
Встановлення значення Maximum buffers Readings дозволяє користувачеві обмежити обсяг пам’яті, який використовується для буферизації в південному сервісі, оскільки коли це значення досягнуто, незалежно від віку даних і налаштування параметра затримки, дані будуть надіслані до сервіса зберігання. Встановлення цього значення на менше значення дозволяє точніше контролювати обсяг пам’яті за рахунок менш ефективного використання сервіса зв’язку та зберігання.
Налаштування між продуктивністю, затримкою та використанням пам’яті завжди є балансуванням. Бувають ситуації, коли вимоги до продуктивності означають, що знадобиться висока затримка, щоб максимально ефективно використовувати зв’язок між мікросервісами та транснаціональною продуктивністю. механізму зберігання. Так само ресурси пам'яті, доступні для буферизації, можуть обмежувати продуктивність, яку можна отримати.
Розширена конфігурація Півночі
Подібно до південних сервісів, північні сервіси та завдання також мають розширену конфігурацію, яку можна використовувати для налаштування роботи північної частини Fledge. Доступ до розширеної конфігурації півночі доступний майже так само, як і південь, виберіть сторінку Північ і відкрийте певний сервіс або завдання півночі. Буде показано екран із вкладками, який містить вкладку Advanced Configuration.
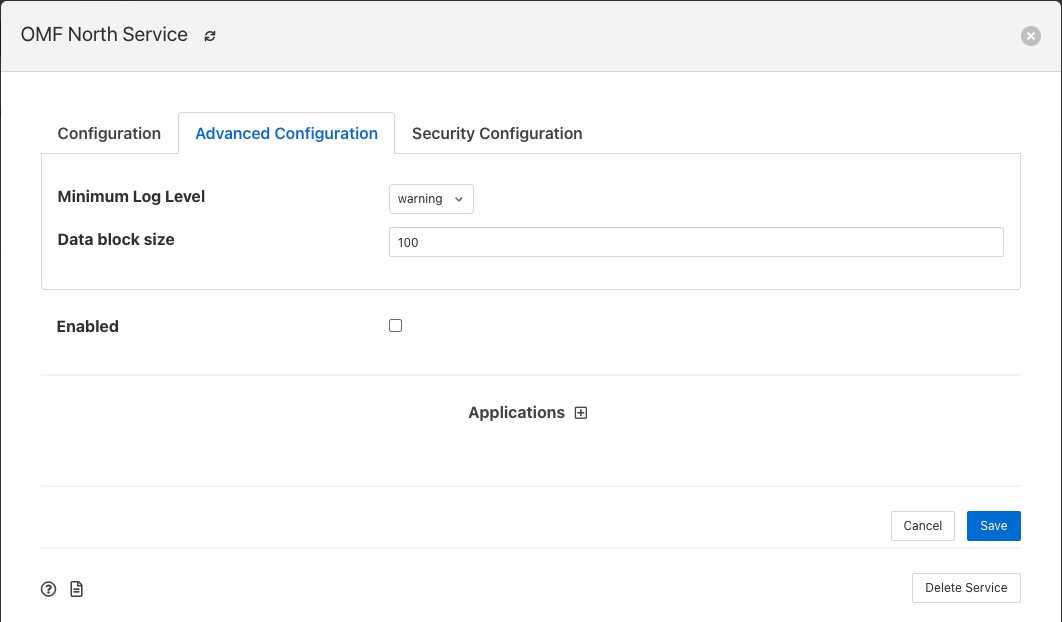
- Minimum Log Level - Цей параметр конфігурації можна використовувати для встановлення журналів, які відображатимуться для цього сервіса чи завдання. Він визначає рівень журналювання, який надсилається до системного журналу, і може бути встановлено на помилка, попередження, інформація або налагодження. Журнали вибраного рівня та вищого рівня надсилатимуться до системного журналу. Ви можете отримати доступ до вмісту цих журналів, вибравши значок журналу в нижньому лівому куті цього екрана.
- Data block size - Це визначає кількість показань, які будуть надіслані до північного плагіна для кожного виклику до точки входу plugin_send. Це дозволяє регулювати продуктивність північного трубопровода даних, збільшуючи розміри блоків, збільшуючи продуктивність, зменшуючи накладні витрати, але за рахунок потреби в більшій кількості пам’яті в північному сервісі або завданні для буферизації даних під час проходження через трубопровід. Якщо встановити занадто високе значення, це може спричинити проблеми для деяких плагінів Півночі, які мають обмеження на кількість повідомлень, які вони можуть обробити в межах одного блоку.
- Asset Tracker Update - Це визначає, як часто засіб відстеження активів очищає кеш інформації відстеження активів на рівень зберігання. Це значення, виражене в мілісекундах. Засіб відстеження активів лише записує оновлення, тому, якщо у вас є фіксований набір активів, що надходять у тубопровід, засіб відстеження активів записуватиме будь-які дані лише під час першого перегляду кожного активу, а потім не виконуватиме подальших записів. Якщо у вас є мінливість у ваших активах або структурі активів, засіб відстеження активів буде більш активним, і стане кориснішим налаштувати цей параметр.
- Performance Counters - Цей параметр дозволяє збирати лічильники продуктивності, які можна використовувати для налаштування північного сервіса.
Лічильники продуктивності
Кілька лічильників продуктивності можна зібрати в північному сервісі, щоб допомогти охарактеризувати продуктивність сервіса. Це призначено для надання вхідних даних для налаштування сервіса, і збір цих лічильників не слід залишати ввімкненим під час використання сервіса в робочих умовах.
Лічильники продуктивності збираються в сервісі, а звіт записується раз на хвилину на рівень зберігання для подальшого отримання. Записані значення є
- Мінімальне значення лічильника, що спостерігається протягом поточної хвилини
- Максимальне значення лічильника, що спостерігається протягом поточної хвилини
- Середнє значення лічильника, що спостерігається протягом поточно�ї хвилини
- Кількість зразків лічильника, зібраних протягом поточної хвилини
У поточному випуску лічильники продуктивності можна отримати лише шляхом прямого доступу до бази даних конфігурації та статистики, вони зберігаються в таблиці monitors. Майбутні випуски включатимуть інструменти для отримання та аналізу цих лічильників продуктивності.
Щоб отримати доступ до лічильників продуктивності через REST API,
використовуйте точку входу /fledge/monitors, щоб отримати всі
лічильники, або /fledge/monitor/{service name}, щоб отримати
лічильники для одного сервіса.
$ curl -s http://localhost:8081/fledge/monitors | jq
{
"monitors": [
{
"monitor": "storedReadings",
"values": [
{
"average": 102,
"maximum": 102,
"minimum": 102,
"samples": 20,
"timestamp": "2024-02-19 16:33:46.690",
"`service`": "si"
},
{
"average": 102,
"maximum": 102,
"minimum": 102,
"samples": 20,
"timestamp": "2024-02-19 16:34:46.713",
"`service`": "si"
},
{
"average": 102,
"maximum": 102,
"minimum": 102,
"samples": 20,
"timestamp": "2024-02-19 16:35:46.736",
"`service`": "si"
}
]
},
{
"monitor": "readLatency",
"values": [
{
"average": 2055,
"maximum": 2064,
"minimum": 2055,
"samples": 20,
"timestamp": "2024-02-19 16:33:46.698",
"`service`": "si"
},
{
"average": 2056,
"maximum": 2068,
"minimum": 2053,
"samples": 20,
"timestamp": "2024-02-19 16:34:46.719",
"`service`": "si"
},
{
"average": 2058,
"maximum": 2079,
"minimum": 2056,
"samples": 20,
"timestamp": "2024-02-19 16:35:46.743",
"`service`": "si"
}
]
},
{
"monitor": "ingestCount",
"values": [
{
"average": 34,
"maximum": 34,
"minimum": 34,
"samples": 60,
"timestamp": "2024-02-19 16:33:46.702",
"`service`": "si"
},
{
"average": 34,
"maximum": 34,
"minimum": 34,
"samples": 60,
"timestamp": "2024-02-19 16:34:46.724",
"`service`": "si"
},
{
"average": 34,
"maximum": 34,
"minimum": 34,
"samples": 60,
"timestamp": "2024-02-19 16:35:46.748",
"`service`": "si"
}
]
},
{
"monitor": "queueLength",
"values": [
{
"average": 55,
"maximum": 100,
"minimum": 34,
"samples": 60,
"timestamp": "2024-02-19 16:33:46.706",
"`service`": "si"
},
{
"average": 55,
"maximum": 100,
"minimum": 34,
"samples": 60,
"timestamp": "2024-02-19 16:34:46.729",
"`service`": "si"
},
{
"average": 55,
"maximum": 100,
"minimum": 34,
"samples": 60,
"timestamp": "2024-02-19 16:35:46.753",
"`service`": "si"
}
]
}
]
}
Коли збір увімкнено, для ввімкненої південної сервіси збиратимуться такі лічильники.
| Лічильник | Опис | Причини та заходи щодо усунення |
|---|---|---|
| No of waits for data | Цей лічильник повідомляє, скільки разів північний сервіс запитував дані зі сховища, але дані були недоступні. | Якщо це значення стабільно низьке або дорівнює нулю, це означає, що інші сервіси надають дані швидше, ніж північний сервіс може надіслати ці дані. Підвищення пропускної здатності північного сервіса було б доцільним, щоб запобігти накопиченню ненадісланих даних у сервісі зберігання. |
| Block utilisation % | Дані зчитуються північним сервісом блоками, розмір цих блоків визначається в розширеній конфігурації північного сервісу. Цей лічильник відображає, який відсоток запитаних блоків фактично заповнюється даними під час кожного звернення до сервіса зберігання. | Постійно високий рівень використання свідчить про те, що доступно більше даних, ніж можна надіслати. Збільшення розміру блоку може покращити цю ситуацію та забезпечити високу пропускну здатність. |
| Reading sets buffered | Це лічильник кількості блоків, які очікують відправлення в північні сервіси | якщо ця цифра перевищує пару блоків, це означає, що північний плагін не може надіслати повні блоки даних і що часткові блоки не надсилаються. Зменшення розміру блоку може покращити ситуацію та змен�шити обсяг пам’яті, необхідного для північного сервіса. |
| Total readings buffered | Це підрахунок загальної кількості показань, буферизованих у північному сервісі. | Це має бути еквівалентно розміру 2 або 3 блоків, які варто зчитувати. Якщо він високий, це свідчить про те, що північний плагін не може підтримувати достатньо високу швидкість передачі даних, щоб відповідати швидкості прийому даних системи. |
| Readings sent | Це дає індикацію для кожного блоку, скільки показань надіслано в блоці. | Зазвичай це має збігатися з прочитаними блоками, якщо ні, це вказує на помилки надсилання даних північним плагіном. |
| Percentage readings sent | Тісно пов’язаний з вищезазначеним Readings sent відсоток кожного прочитаного блоку, який фактично було надіслано. | У добре налаштованій системі ця цифра має бути близькою до 100%, якщо це не так, можливо, північний плагін не може надіслати дані, можливо, через проблему у системі, що стоїть вище. Крім того, розмір блоку може бути занадто високим, щоб система, що виходить, могла впоратися, і зменшення розміру блоку наблизить це значення до 100%. |
| Readings added to buffer | Абсо�лютна кількість показань, зчитаних у кожному блоці. | Якщо це значення значно менше розміру блоку, це означає, що розмір блоку можна зменшити. Якщо він завжди близький до розміру блоку, подумайте про збільшення розміру блоку. |
Моніторинг "здоров'я"
Ядро Fledge відстежує працездатність інших сервісів у Fledge, це
робиться за допомогою service Monitor у Fledge і може бути налаштовано
за допомогою пункту меню Configuration в інтерфейсі користувача
Fledge. На сторінці конфігурації виберіть параметри Advanced, а потім
розділ service Monitor.
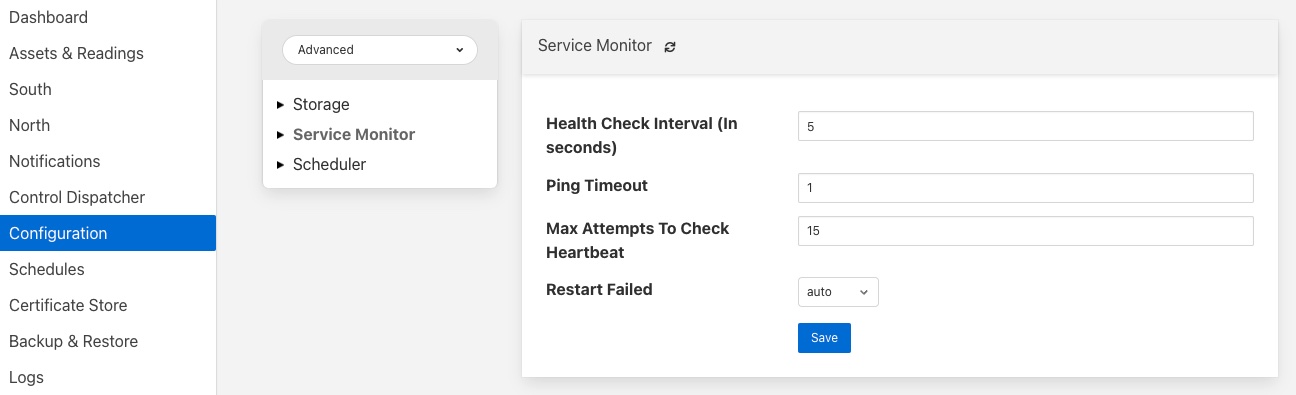
- Health Check Interval - Цей параметр визначає, як часто Fledge надсилатиме запит на перевірку працездатності кожному з мікросервісів у примірнику Fledge. Значення виражається в секундах. Зробивши це значення малим, ви зменшите кількість часу, необхідного для виявлення збо�ю, але збільшите навантаження на систему для виконання перевірок справності. Якщо робити це занадто часто, ймовірно, збільшиться кількість помилкових виявлень помилок.
- Ping Timeout - Час очікування в секундах, перш ніж оголосити про помилку перевірки працездатності. Якщо відповідь на перевірку справності не буде помічено протягом цього часу, сервіс буде вважатися таким, що не відповідає. Невеликі значення можуть призвести до того, що зайняті сервіси стають підозрілими помилково.
- Max Attempts To Check Heartbeat - Це кількість запитів серцевого ритму, які мають завершитися невдачею, перш ніж ядро визначить, що в сервісі стався збій, і спробує будь-яку відновну дію. Зменшення цього значення призведе до того, що сервіс буде оголошений як несправний раніше, і, отже, відновлення можна буде виконати швидше. Якщо це значення замале, це може призвести до кількох екземплярів роботи сервіса або частих перезапусків. Якщо зробити це надто довго, це призведе до втрати даних.
- Restart Failed - Визначте, які дії слід виконати, якщо сервіс виявлений як несправний. Доступні два варіанти: Manual, у цьому випадку дії не виконуватимуться автоматично, або Auto, у цьому випадку послугу буде автоматично перезапущено.
Планувальник
Ядро Fledge містить планувальник, який використовується для запуску періодичних завдань, цей планувальник має кілька параметрів налаштування. Щоб отримати доступ до цих параметрів з інтерфейсу користувача Fledge, на сторінці конфігурації виберіть параметри Advanced, а потім розділ Scheduler.

- Max Running Tasks - Визначає максимальну кількість завдань, які можуть бути запущені в будь-який час. Цей параметр призначений для зупинки невиконуваних завдань, які негативно впливають на продуктивність системи. Коли це число буде досягнуто, нові завдання не створюватимуться, доки не буде припинено одне або кілька поточних завдань. Установіть занадто низьке значення, і ви не зможете виконувати всі необхідні завдання паралельно. Установіть занадт�о високе значення, і система піддається більшому ризику від невиконуваних завдань.
- Max Age of Task - Визначає тривалість виконання завдання в днях. Завдання, які виконуються довше, ніж це, буде знищено системою.
Примітка Окремі завдання мають налаштування, які вони можуть використовувати для зупинки кількох екземплярів одного завдання, що иконуються паралельно. Це також допомагає захистити систему від невиконуваних завдань.
Початкове замовлення
Планувальник Fledge також забезпечує впорядкування послідовності запуску різних сервісів в екземплярі Fledge. Це гарантує, що сервіси підтримки запускаються до запуску будь-яких південних або північних сервісів, а південні сервіси запускаються перед північними.
Немає впорядкування в південних або північних сервісах, усі південні сервіси запускаються в одному блоці, та всі північні – в одному блоці.
Порядок, у якому запускається сервіс, контролюється шл�яхом призначення послуги пріоритету. Цей пріоритет є числовим значенням, і сервіси запускаються на основі цього значення. Чим менше значення, тим раніше в послідовності запускається сервіс.
Пріоритети зберігаються в таблиці бази даних, scheduled_processes. Наразі немає інтерфейсу користувача для зміни пріоритету запланованих процесів, але його можна змінити шляхом прямого доступу до бази даних. Майбутні версії Fledge можуть додати інтерфейс для налаштування пріоритетів запуску процесу.
Зберігання
Рівень зберігання, мабуть, є однією з областей, яка найбільше впливає на загальну продуктивність примірника Fledge, оскільки це кінцева точка для трубопроводів даних; місце, де закінчуються всі трубопроводи на півдні, і точка виходу всіх трубопроводів на північ до зовнішніх систем.
Система зберігання у Fledge служить двом цілям
- Зберігання конфігурації та постійного стану самого Fledge
- Буферизація зчитування даних під час проходження примірника Fledge
Фізичн�им сховищем керують плагіни, які динамічно завантажуються в сервіс зберігання так само, як і інші сервіси у Fledge. У випадку зі сервісом зберігання він може мати один або два завантажених плагіни. Якщо завантажується один плагін, він використовуватиметься для зберігання конфігурації та показань; якщо завантажено два плагіни, один використовуватиметься для збереження конфігурації, а інший для зберігання показань. Не всі плагіни підтримують обидва класи даних.
Вибір плагіна зберігання
Fledge постачається з низкою плагінів для зберігання, які можна використовувати, кожен із них має свої переваги та обмеження. Нижче наведено огляд кожного з плагінів, які наразі включено до Fledge.
sqlite
Плагін зберігання за умовчанням, який використовується. Він реалізований
за допомогою бази даних SQLite і здатний зберігати дані конфігурації
та читання. Його оптимізовано, щоб дозволити паралелізм, коли в
екземпляр Fledge �надходить кілька активів. Однак він має обмеження щодо
кількості різних активів, які можна отримати в межах екземпляра. Точне
обмеження залежить від низки інших факторів, але становить близько 900
унікальних назв активів на екземпляр. Це хороший плагін для зберігання
даних загального призначення, який може керувати досить високою
швидкістю читання даних.
sqlitelb
Це ще один плагін на основі SQLite, здатний зберігати як показання,
так і конфігураційні дані. Він призначений для даних з меншою пропускною
здатністю, звідси суфікс назви lb. Він не має такої ж оптимізації
паралелізму, як плагін sqlite за замовчуванням, і, отже, є менш
ефективним, коли надходять високошвидкісні дані, розподілені між
кількома активами. Однак він добре працює, коли отримує високі показники
для одного активу або низькі показники для дуже великої кількості
активів. Він не має жодних обмежень щодо кількості різних активів, які
можна зберігати в примірнику Fledge.
sqlitememory
Це плагін на основі SQLite, який використовує таблиці пам’яті та може
використовуватися лише для зберігання даних для читання, його потрібно
використовувати разом з іншим плагіном, який використовуватиметься для
збереження конфігурації. Дані для читання зберігаються в таблицях у
пам’яті, тому можуть підтримуватися дані з дуже високою пропускною
здатністю. Однак якщо Fledge вимкнеться, дані, що зберігаються в цих
таблицях, буде втрачено.
postgres
Цей плагін реалізовано за допомогою бази даних PostgreSQL і підтримує
зберігання даних конфігурації та читання. Він використовує стандартний
механізм зберігання Postgres і отримує переваги від додаткових функцій
Postgres для безпеки та реплікації. Він здатний підтримувати високий
рівень паралелізму, але має дещо нижчу загальну продуктивність, ніж
плагіни sqlite. Postgres також погано працює з певними типами носіїв
інформації, такими як SD-карти, оскільки він має вищу швидкість
зберігання на носіях.
У більшості випадків плагін зберігання sqlite за замовчуванням цілком прийнятний, однак, якщо завантажуються дуже високі швидкості передачі даних або величезні обсяги даних (тобто великі зображення з досить високою швидкістю), цей плагін може почати вияв�ляти проблеми. Зазвичай це проявляється у створенні великих черг у південному сервісі або, у крайніх випадках, у повідомленнях про помилку транзакцій у журналі сервіса зберігання. Якщо це станеться, рекомендовано або перейти на плагін, який зберігає дані в пам’яті, а не на зовнішній пам’яті, sqlitememory, або дослідити носій, на якому зберігаються дані. Низька продуктивність сховища негативно вплине на плагін sqlite.
Плагін sqlite також може виявитися менш оптимальним, якщо ви завантажуєте багато сотень різних активів в один екземпляр Fledge. Плагін sqlite було оптимізовано, щоб дозволити паралельним південним сервісом записувати в сховище паралельно. Це досягається шляхом використання кількох баз даних для покращення паралельності, однак існує обмеження, яке накладається кількістю відкритих баз даних, які можна підтримувати. Якщо цей ліміт перевищено, рекомендуємо перейти на плагін sqlitelb. Існують параметри конфігурації щодо того, як використовуються ці бази даних, які можуть змінити момент, коли виникає необхідність перейти на інший плагін.
Якщо ви бажаєте використовувати один і то�й самий плагін для зберігання конфігураційних даних і даних для читання, ви можете або вибрати той самий плагін для обох, або вибрати параметр Use main plugin для значення Reading Plugin. Використовувати пізніший варіант, мабуть, є трохи безпечнішим, оскільки зміни в Storage Plugin автоматично призведуть до того, що показання використовуватимуть той самий плагін.
Налаштування плагінів зберігання
Плагіни зберігання для використання можна вибрати в розділі Advanced на сторінці Configuration. Виберіть категорію Storage з дерева категорій, і відобразиться наступне.
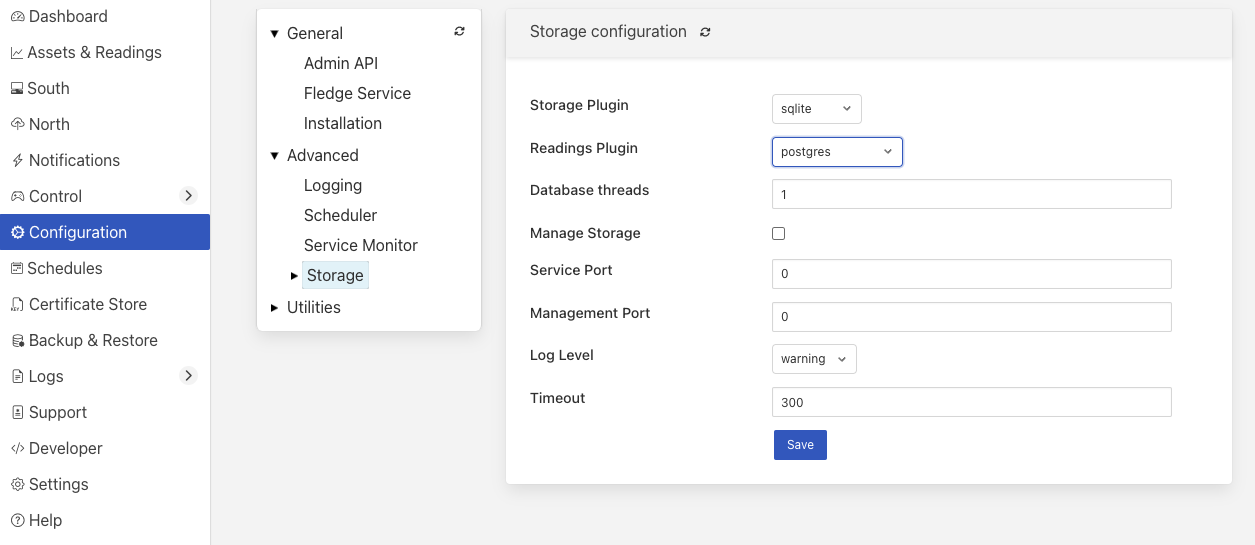
- Storage Plugin: Назва плагіна зберігання, який буде використано. Він використовуватиметься для зберігання конфігураційних даних і має бути одним із підтримуваних плагінів зберігання.
Примітка Це не може бути плагін sqlitememory, оскільки він не підтримує зберігання конфігурації.
- Reading Plugin: Назва плагіна зберігання, який використовуватиметься для зберігання даних зчитувань. Якщо залишити порожнім, Storage Plugin вище буде використовуватися для зберігання конфігурації та показань.
- Database threads: Збільшує кількість потоків, які використовуються в сервісі зберігання для керування активністю бази даних. Це не та кількість потоків, які можна використовувати для читання або запису бази даних, і збільшення цієї кількості не покращить пропускну здатність даних.
- Manage Storage: Це використовується, коли використовується програма зовнішнього зберігання, наприклад база даних Postgres, яка потребує окремої ініціалізації. Якщо цей зовнішній процес не запущено за замовчуванням, установивши значення true, Fledge запустить процес зберігання. Зазвичай це не потрібно, оскільки Postgres слід запускати як системний сервіс, а SQLite цього не вимагає.
servicePort: Зазвичай сервіс зберігання динамічно створює порт сервіса, який використовуватиметься сервісом зберігання. Якщо встановити значення, відмінне від 0, використовуватиметься фіксований порт. Це може бути корисним під час розробки нового плагіну для зберігання або для надання доступу додатку, який не належить до Fledge, до рівня зберігання. Це слід змінювати лише з особливою обережністю.- Management Port: Зазвичай сервіс зберігання динамічно створює порт керування, який використовуватиметься сервісом зберігання. Якщо встановити значення, відмінне від 0, використовуватиметься фіксований порт. Це може бути корисним під час розробки нового плагіну зберігання.
- Log Level: Це визначає рівень, на якому плагін зберігання буде виводити логи.
- Timeout: Встановлює значення часу очікування в секундах для кожного запиту до рівня зберігання. Це призводить до повернення клієнту помилки тайм-ауту, якщо виклик зберігання займає більше часу, ніж указане значення.
Зміни буде збережено після натискання кнопки save. Fledge використовує механізм, за допомогою якого ці дані не лише зберігаються в базі даних конфігурації, але й кешуються у файлі під назвою storage.json у каталозі etc каталогу даних. Це потрібно д�ля того, щоб Fledge міг знайти базу даних конфігурації під час процесу завантаження. Якщо конфігурація з якоїсь причини буде пошкоджена, просто видаліть цей файл і перезапустіть Fledge, що призведе до відновлення конфігурації за замовчуванням. Розташування каталогу даних Fledge залежатиме від способу встановлення Fledge та змінних середовища, які використовуються для запуску Fledge.
- Встановлення з пакету зазвичай розміщує каталог даних у /usr/local/fledge/data. Однак це можна змінити, встановивши змінну середовища $FLEDGE_DATA так, щоб вона вказувала на інше розташування.
- Під час запуску копії Fledge, створеної з джерела, каталог даних
можна знайти в
${FLEDGE_ROOT}/data. Знову ж таки, це можна змінити, встановивши змінну середовища $FLEDGE_DATA.
Примітка У разі зміни сервіси зберігання потрібно перезавантажити екземпляр Fledge, перш ніж використовувати нові плагіни зберігання. Крім того, дані не переносяться з одного плагіна в інший, тому, якщо в базі даних є ненадіслані дані, вони будуть втрачені під час зміни плагіна зберігання. Однак плагіни sqlite та sqlitelb спільно використовують однакові таблиці даних к�онфігурації, тому конфігурація буде збережена під час переходу між цими базами даних, але читання даних не буде.
Налаштування Плагіну sqlite
Конфігурацію плагіна зберігання можна знайти в розділі Advanced на сторінці Configuration. Виберіть категорію Storage на панелі дерева категорій і назву плагіна під цією категорією. У випадку плагіна зберігання sqlite буде показано наступне.
-
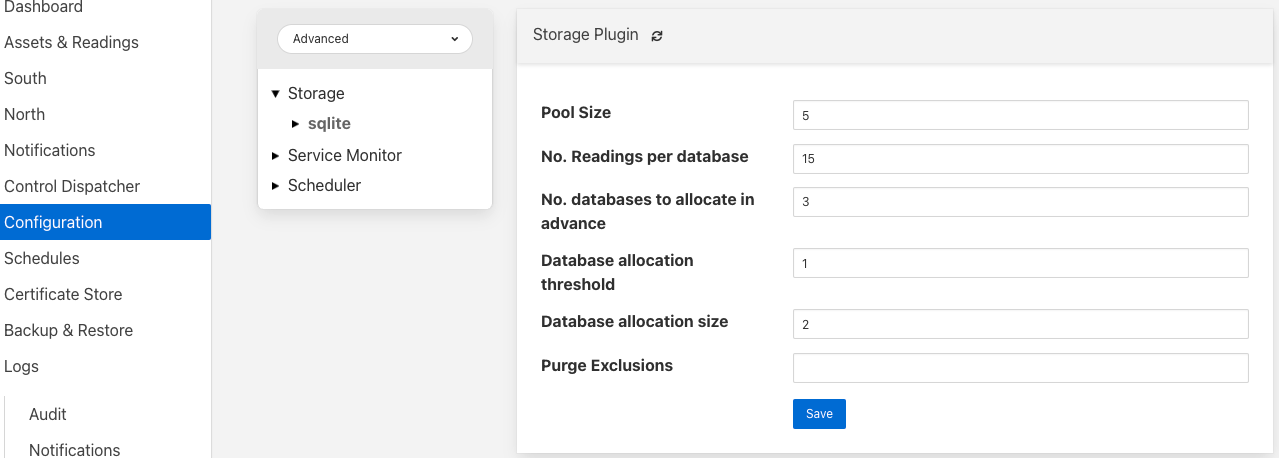
Pool Size: сервіс зберігання використовує пул з’єднань для зв’язку з основною базою даних, саме цей розмір пулу визначає, скільки паралельних операцій можна викликати в базі даних.
Цей розмір пулу є лише початковим розміром, сервіс зберігання збільшить пул, якщо потрібно, однак встановлення реалістичного початкового розміру пулу покращить продуктивність Fledge.
Примітка Хоча розмір пулу вказує на кількість паралельних операцій, які можуть виконуватися, розгляд щодо блокування бази даних може зменшити кількість фактичних операцій, що виконуються в будь-який момент часу.
- No. Readings per database: Плагін sqlite підтримує кілька баз даних зчитування, з іменем активу, який використовується для визначення бази даних, у якій зберігати зчитування. Це покращує рівень паралелізму, зменшуючи конфлікти блокувань під час запису даних. Якщо встановити для цього значення значення 1, в одній базі даних показань зберігатиметься лише одне ім’я активу, що призведе до відсутності суперечок між активами. Однак існує обмеження на кількість баз даних, тому встановлення значення 1 обмежить кількість різних активів, які можна ввести в примірник.
- No. databases to allocate in advance: Це визначає, скільки баз даних для читання Fledge має створити спочатку. Створення баз даних є повільним процесом, тому його найкраще досягти до того, як дані почнуть надходити через Fledge. Встановлення занадто високого значення призведе до того, що Fledge виділить велику кількість баз даних, ніж потрібно, і втратить відкриті підключення до бази даних. В ідеалі встановіть кількість різних активів, які ви очікуєте отримати, поділену на кількість читань для кожної конфігурації бази даних вище. Це має надати вам достатньо баз даних для зберігання потрібних вам даних.
- Database allocation threshold: Розподіл нової бази даних є повільним процесом, тому замість того, щоб чекати, доки не залишиться доступних баз даних, перш ніж розподіляти нові, можна попередньо виділити базу даних, оскільки кількість вільних баз даних стає малою. Це значення дозволяє встановити точку, на якій потрібно розподілити більше баз даних. Як тільки кількість вільних баз даних зменшиться до цього значення, плагін виділить більше баз даних.
- Database allocation size: Кількість нових баз даних, які потрібно створити щоразу, коли відбувається розподіл. Це фактично вказує на розмір вільного пулу баз даних, який потрібно створити.
- Purge Exclusion: це не налаштування продуктивності, але дозволяє виключити низку активів із процесу очищення. Це значення — розділений комами список назв активів, які буде виключено з операції очищення.
- Vacuum Interval: Інтервал між виконанням вакуумних операцій над базою даних, виражений у годинах. Операція вакуумування використовується для відновлення місця в базі даних від видалених даних.
Налаштування sqlitelb
Конфігурацію плагіна зберігання можна знайти в розділі Advanced на сторінці Configuration. Виберіть категорію Storage на панелі дерева категорій і назву плагіна під цією категорією. У випадку плагіна зберігання sqlitelb буде показано наступне.

Примітка Конфігурація sqlite все ще присутня та доступна для вибору, оскільки цей екземпляр раніше запускав цей плагін для зберігання, і конфігурація зберігається під час перемикання між плагінами sqlite і sqlitelb.
-
Pool Size: сервіс зберігання використовує пул з’єднань для зв’язку з основною базою даних, саме цей розмір пулу визначає, скільки паралельних операцій можна викликати в базі даних.
Цей розмір пулу є лише початковим розміром, сервіс зберігання збільшить пул, якщо потрібно, однак встановлення реалістичного початкового розміру пулу покращить продуктивність Fledge.
Примітка Хоча розмір пулу вказує на кількість паралельних операцій, які можуть виконуватися, розгляд щодо блокування бази даних можуть зменшити кількість фактичних операцій, що виконуються в будь-який момент часу.
- Vacuum Interval: Інтервал між виконанням вакуумних операцій над базою даних, виражений у годинах. Операція вакуумування використовується для відновлення місця в базі даних видаленими даними.
- Purge Block Size: Максимальна кількість рядків, які буде видалено в межах однієї транзакції під час виконання операції очищення даних показань. Великі розміри блоків є потенційно найефективнішими з точки зору часу для завершення операції очищення, однак це збільшить суперечку за базою даних, оскільки потрібне блокування бази даних, яке призведе до зупинки будь-яких операцій надходження, доки не завершиться очищення. Якщо встановити менший розмір блоку, очищення триватиме довше, але операції прийому можна чергувати з очищенням блоків.
Налаштування postgres
Конфігурацію плагіна зберігання можна знайти в розділі Advanced на сторінці Configuration. Виберіть категорію Storage на панелі дерева категорій і назву плагіна під цією категорією. У випадку плагіна зберігання postgres буде показано наступне.
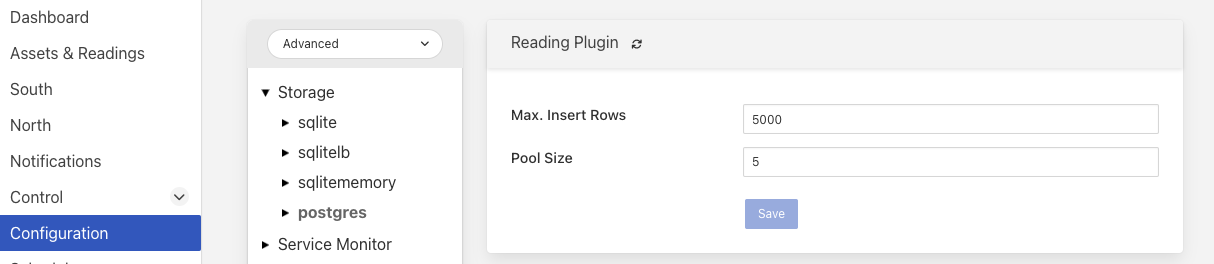
Pool Size: сервіс зберігання використовує пул з’єднань для зв’язку з основною базою даних, саме цей розмір пулу визначає, скільки паралельних операцій можна викликати в базі даних.
Цей розмір пулу є лише початковим розміром, сервіс зберігання збільшить пул, якщо потрібно, однак встановлення реалістичного початкового розміру пулу покращить продуктивність Fledge.
Max. Insert Rows: Максимальна кількість показань, які будуть вставлені в один виклик Postgres. Це параметр налаштування, який має дві дії на систему
обмежує розмір і, отже, вимоги до пам'яті для одного оператора вставки
запобігає блокуванню доступу до таблиці читань дуже довготривалими транзакціями вставки
Цей параметр корисний у системах із дуже високою швидкістю прийому даних або коли прийом містить спорадичні великі спалахи зчитування, щоб обмежити використання активів і суперечки щодо блокування бази даних.
Примітка Хоча розмір пулу вказує на кількість паралельних операцій, які можуть виконуватися, розгляд щодо блокування бази даних можуть зменшити кількість фактичних операцій, що виконуються в будь-який момент часу.
Налаштування sqlitememory
Конфігурацію плагіна зберігання можна знайти в розділі Advanced на сторінці Configuration. Виберіть категорію Storage на панелі дерева категорій і назву плагіна під цією категорією. Оскільки цей плагін підтримує лише зберігання показа�нь, завжди буде відображатися принаймні один інший модуль читання. Після вибору плагіна зберігання sqlitememory відобразиться наступне.
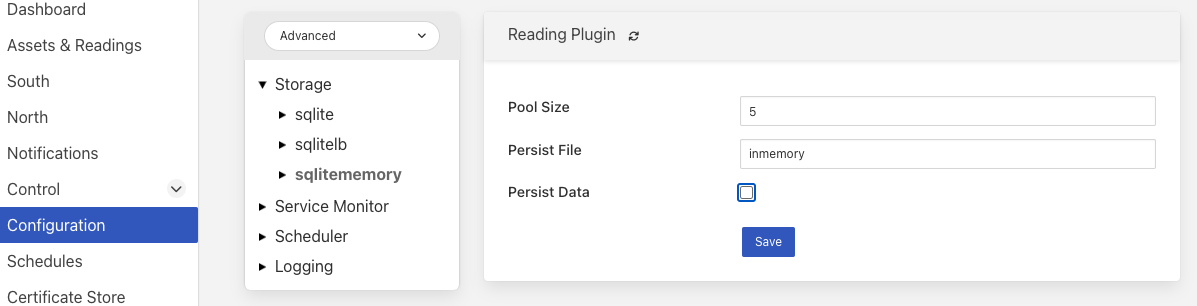
Pool Size: сервіс зберігання використовує пул з’єднань для зв’язку з базовою базою даних, саме цей розмір пулу визначає, скільки паралельних операцій можна викликати в базі даних.
Цей розмір пулу є лише початковим розміром, сервіс зберігання збільшить пул, якщо потрібно, однак встановлення реалістичного початкового розміру пулу покращить продуктивність Fledge.
Примітка Хоча розмір пулу вказує на кількість паралельних операцій, які можуть виконуватися, розгляд щодо блокування бази даних можуть зменшити кількість фактичних операцій, що виконуються в будь-який момент часу..
- Persist Data: Контролює збереження бази даних у пам’яті після завершення роботи. Якщо ввімкнено, база даних у пам’яті зберігатиметься після завершення роботи Fledge і перезавантажуватиметься під час наступного за�пуску Fledge. Вибір цього параметра сповільнить процес завершення роботи та запуску Fledge.
- Persist File: Визначає ім’я файлу, до якого буде зберігатися база даних у пам’яті.
- Purge Block Size: Максимальна кількість рядків, які буде видалено в межах однієї транзакції під час виконання операції очищення даних показань. Великі розміри блоків є потенційно найефективнішими з точки зору часу для завершення операції очищення, однак це збільшить суперечку за базою даних, оскільки потрібне блокування бази даних, яке призведе до зупинки будь-яких операцій надходження, доки не завершиться очищення. Якщо встановити менший розмір блоку, очищення триватиме довше, операції прийому гайки можна чергувати з очищенням блоків.
Лічильники продуктивності
У службі зберігання даних можна збирати кілька лічильників продуктивності, які допоможуть охарактеризувати роботу служби. Ці лічильники призначені для налаштування сервісу, і їх не слід залишати увімкненими під час використання сервісу у виробничих цілях.
Лічильники продуктивності вмикаються і вимикаються за допомогою перемикача у конфігурації служби зберігання, який можна знайти, вибравши пункт Додатково у показаних категоріях сторінки конфігурації. Потім виберіть категорію "Сховище" в розділі "Додатково" з дерева категорій. Буде показано наступне.
Прапорець Лічильники продуктивності вказує на поточний стан збору статистики рівня зберігання. На відміну від деяких інших пунктів цієї категорії конфігурації, він не вимагає перезавантаження системи для того, щоб нові налаштування набули чинності.
Лічильники продуктивності збираються у службі зберігання даних, а звіт записується раз на хвилину до бази даних конфігурації для подальшого пошуку. Записуються такі значення
- Мінімальне значення лічильника, зафіксоване протягом поточної хвилини.
- Максимальне значення лічильника, яке спостерігалося протягом поточної хвилини.
- Середнє значення лічильника, що спостерігалося протягом поточної хвилини.
- Кількість зразків лічильника, зібраних протягом поточної хвилини. Оскільки одна вибірка робиться за один виклик API сховища, це значення фактично дає вам кількість викликів вставки, оновлення, видалення або додавання читання, зроблених до рівня сховища. У поточній версії лічильники продуктивності можна отримати лише за допомогою прямого доступу до бази даних конфігурації та статистики, вони зберігаються в таблиці monitors. Або через REST API. У майбутніх випусках будуть додані інструменти для отримання та аналізу цих лічильників продуктивності.
Щоб отримати доступ до лічильників продуктивності через REST API, використовуйте точку входу /fledge/monitors, щоб отримати всі лічильники, або /fledge/monitors/Storage, щоб отримати лічильники тільки для служби зберігання.
Якщо збір увімкнено, наступні лічильники будуть збиратися для увімкненого сервісу зберігання даних.
| Лічильник | Опис | Причини та дії щодо усунення |
|---|---|---|
| Зчитування Час додатка (мс) | Час, необхідний для додавання показань до системи зберігання даних | Високі значення цього показника можуть бути наслідком високого рівня конфліктів у системі або якщо базова система зберігання даних не має достатньої пропускної здатності, щоб впоратися зі швидкістю надходження даних. Для зменшення високих значень цього показника можна спробувати кілька способів. Зменшення кількості викликів за рахунок збільшення максимального розміру блоку та налаштування затримки в службі south. Перехід на швидший плагін або покращення підсистеми зберігання даних на машині, де встановлено Fledge. |
Зчитування Додавання рядків <плагіна> | Кількість зчитувань, що вставляються при кожному зверненні до рівня зберігання | Низькі значення цього параметра можуть свідчити про те, що на південних сервісах налаштовано або занадто низьке значення затримки, або занадто низьку максимальну кількість зчитувань у буфері. Якщо продуктивність недостатня, то збільшення кількості зчитувань, що надсилаються до служби зберігання за один виклик, може покращити продуктивність. |
Зчитування Додавання розміру навантаження <плагіна> | Розмір корисного навантаження JSON, що містить зчитування | Великі розміри корисного навантаження з малою кількістю рядків вказують на дуже багатий вміст зчитування, зменшення розміру корисного навантаження шляхом фільтрації або обробки даних покращить продуктивність і зменшить вимоги до сховища для екземпляра Fledge. |
Двставити рядки <таблиця> | Набір лічильників, по одному на таблицю, які показують кількість вставок в таблицю протягом однієї хвилини збору даних. Кількість вибірок дорівнює кількості викликів API сховища для вставки рядків. Мінімальне, середнє та максимальне значення вказує на кількість рядків, вставлених за один виклик вставки | Дії, які слід вжити, дуже сильно залежать від того, про яку таблицю йдеться. Наприклад, якщо це таблиця статистики, то зменшення кількості статистичних даних, які підтримує система, зменшить навантаження на систему для їх зберігання. |
Оновити рядки <таблиця> | Набір лічильників, по одному на таблицю, які показують кількість оновлень таблиці протягом однієї хвилини збору даних. Кількість вибірок дорівнює кількості викликів API сховища для оновлення рядків. Мінімальне, середнє та максимальне значення вказує на кількість рядків, оновлених за один виклик. | Дії, які слід вжити, дуже сильно залежать від того, про яку таблицю йдеться. Наприклад, якщо це таблиця статистики, то зменшення кількості статистичних даних, які підтримує система, зменшить навантаження на систему для їх зберігання. |
Видалити рядки <таблиця> | Набір лічильників, по одному на таблицю, які показують кількість викликів видалення, пов'язаних з таблицею, протягом однієї хвилини збору даних. Кількість вибірок дорівнює кількості викликів API сховища для видалення рядків. Мінімальне, середнє та максимальне значення вказують на кількість рядків, видалених за один виклик. | API видалення використовується нечасто, і мало що можна налаштувати, щоб вплинути на його використання. |
Вставити розмір навантаження <таблиця> | Розмір корисного навантаження JSON у вставці звертається до рівня зберігання для даної таблиці. | Кінцевий користувач не може вплинути на розмір корисного навантаження, однак він дає уявлення про використання пропускної здатності API сховища. |
Оновити розмір навантаження <таблиця> | Розмір корисного навантаження JSON в оновленні звертається до рівня зберігання для даної таблиці. | Кінцевий користувач не може вплинути на розмір корисного навантаження, однак він дає уявлення про використання пропускної здатності API сховища. |
Видалити розмір навантаження <таблиця> | Розмір корисного навантаження JSON у викликах видалення до рівня зберігання для даної таблиці. | Кінцевий користувач не може вплинути на розмір корисного навантаження, однак він дає уявлення про використання пропускної здатності API сховища. |
Використання лічильників ефективності
Лічильники ефективності - це спосіб подивитися на конкретні показники в рамках послуги, щоб отримати більш глибоке розуміння ефективності окремих послуг та системи в цілому. У наведеній вище документації описано використання цих лічильників для низки різних послуг, однак для того, щоб допомогти в інтерпретації цих лічильників, корисно глибше зрозуміти, як збираються дані і що вони означають.
Лічильники ефективності впроваджуються всередині послуг для збору даних протягом певного періоду часу та представлення узагальненої інформації про зібрані показники. Кожен лічильник або монітор збирає дані протягом однієї хвилини, після чого зберігаються чотири елементи даних, що стосуються лічильника.
- Кількість зразків, зібраних протягом цієї хвилини.
- Мінімальне значення, зафіксоване протягом хвилини.
- Максимальне значення, що спостері�галося протягом хвилини.
- Середнє значення, що спостерігалося протягом хвилини.
Ці значення записуються навпроти назви лічильника та позначки часу, яка відображає кінець хвилини, протягом якої були зібрані значення.
Вибірка
Вибірка, можливо, є дещо оманливим терміном щодо деяких лічильників. У більшості випадків вибірка робиться, коли відбувається якась подія, наприклад, у випадку зі сховищем кожна вибірка представляє один з API API сховища, який отримує виклик. Таким чином, у випадку зі сховищем кількість вибірок показує кількість викликів API, зроблених протягом хвилини. Ім'я лічильника показує, який саме виклик API це був, а у випадку зі сховищем - також таблицю, до якої цей виклик було зроблено. Значення для цих викликів API розповідають вам про параметри, передані до виклику API.
У південному та північному сервісах події, пов'язані з отриманням, пересиланням та читанням даних. Найчастіше вибірка робиться, коли система обробляє блок даних, який складається з одного або декількох зчитувань. Знову ж таки, кількість вибірок вказує на кількість операцій за хвилину, які виконує сервіс, а значення представляють обсяг даних, що обробляються в більшості випадків.
Визначення вузьких місць
Погляд на довгострокові тенденції лічильників продуктивності, які повідомляють про довжину черги, є корисним способом визначити, де в системі може існувати вузьке місце. В ідеалі довжина черги має бути пропорційною до обсягу даних, що зчитуються, і повинна бути стабільною з часом, якщо обсяги даних стабільні. Якщо вона не є стабільною і зростає, це свідчить про те, що щось на північ від цієї черги не в змозі обробити постійні обсяги даних, що надходять. Якщо довжина черги зменшується, це означає, що щось на південь від черги не справляється з навантаженням, яке їй пропонується.
Збільшення часу обробки може також вказувати на те, що щось на північ від цього місця в конвеєрі або саме місце не може отримати достатній ресурс для підтримки необхідного навантаження на обробку.
Збільшення розмірів корисного навантаження або кількості рядків у випадку лічильників продуктивності сховища вказує на те, що компоненти на південь від лічильника надають дані швидше, ніж вони можуть бути оброблені, і все більше даних буферизуються в цих сервісах.
Видалення моніторів
Монітори продуктивності зберігаються у базі даних конфігурації екземпляра Fledge в одній таблиці з назвою monitors. Вони залишатимуться в базі даних, доки їх не буде видалено вручну. Видалення може бути виконано за допомогою API або шляхом прямого доступу до таблиці бази даних. API для видалення моніторів використовує метод DELETE у виклику API. URL-адреси, що використовуються, ідентичні тим, що використовуються при отриманні лічильників продуктивності. Щоб видалити всі монітори продуктивності, використовуйте URL-адресу /fledge/monitors з методом DELETE, щоб видалити тільки монітори певного сервісу, використовуйте URL-адресу виду /fledge/monitors/service.
curl -X DELETE http://localhost:8081/fledge/monitors
Застереження
Слід бути обережним при використанні лічильників продуктивності, оскільки майже у будь-якій системі акт спостереження за системою впливає на її поведінку. Це, безумовно, стосується і лічильників продуктивності.
- Час збору даних. Хоча внутрішньо лічильники продуктивності зберігаються у структурі пам'яті, вона індексується за іменем лічильника і потребує кінцевого часу для збору даних. Це незначною мірою знижує загальну продуктивність системи.
- Використання пам'яті. Лічильники продуктивності зберігаються у пам'яті, причому значення записуються для кожного зразка. Це може зайняти значний обсяг пам'яті, якщо у системі відбувається велика кількість подій, які спричиняють вибірку даних лічильника продуктивності. Це впливає не лише на розмір системи, але й на продуктивність, оскільки вимагає динамічного розподілу пам'яті.
- Зберігання лічильників. Лічильники продуктивності зберігаються у базі даних конфігурації рівня зберігання. Зберігання цих лічильників не лише збільшує навантаження на систему зберігання даних, викликаючи виклики API для вставки рядків у таблицю моніторів, але й збільшує навантаження на базу даних конфігурації.
- Розростання бази даних. Не існує автоматичного процесу очищення лічильників продуктивності. Це потрібно робити вручну за допомогою API або безпосередньо у таблиці monitors. Примітка: Лічильники продуктивності можуть бути дуже корисним інструментом при налаштуванні або налагодженні систем Fledge, але ніколи не слід залишати їх увімкненими під час продуктивного використання.