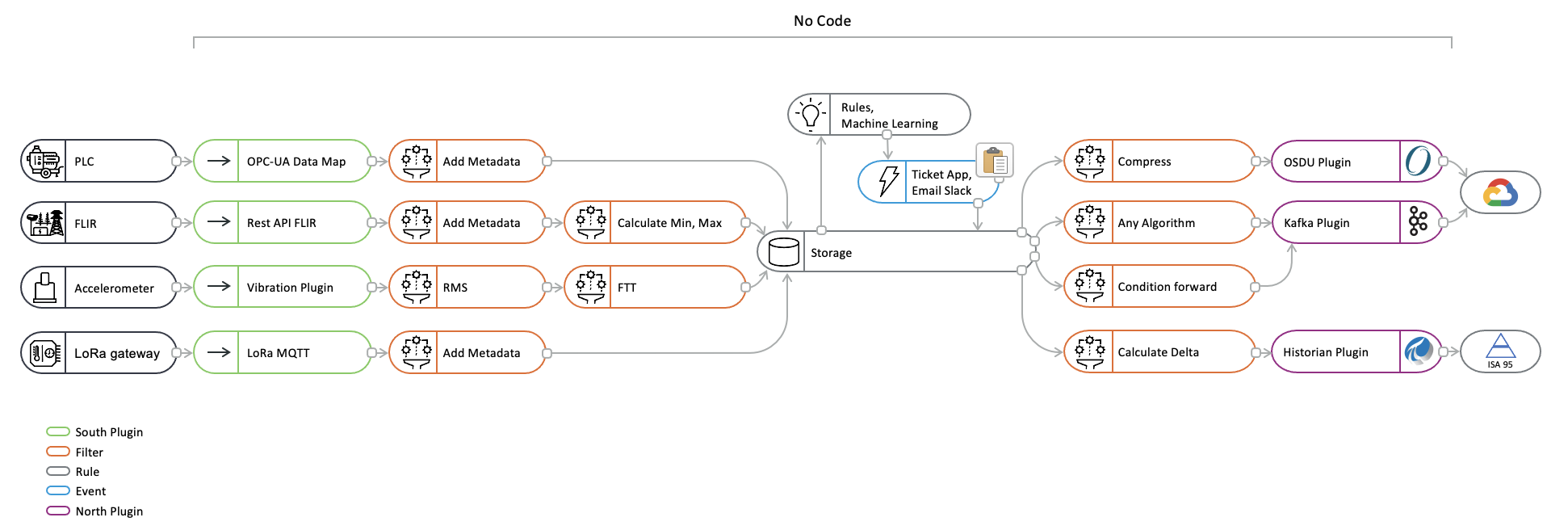
Розробка трубопроводів
Fledge надає систему трубопроводів, яка дозволяє передавати дані від точки їхнього надходження до екземпляру Fledge, південного плагіна, до рівня зберігання, в якому вони буферизуються. Етапи цього трубопроводу є фільтрами обробки Fledge, вихід одного фільтра стає входом наступного. Fledge також підтримує трубопроводи на виході, коли потоки даних передаються з рівня зберігання до північних плагінів і далі до систем, інтегрованих вище за течією від екземпляра Fledge.
Операції в південному сервісі виконуються над даними з одного джерела, в той час як операції в північному сервісі виконуються над даними, що прямують до одного пункту призначення. Фільтруючий трубопровід на півночі буде мати дані з джерел, що протікають через трубопровід, ці дані будуть формувати змішаний потік, який буде містити всі дані в порядку дати/часу.
Найкращі практики
Fledge може підтримувати декілька трубопроводів в одному екземплярі Fledge, однак, якщо у вас є добре налагоджений екземпляр Fledge з критично важливими трубопроводами, які працюють на цьому екземплярі, можливо, не завжди є найкращою практикою розробляти новий, експериментальний трубопровод на тому ж екземплярі Fledge.
Розглянемо спочатку південні плагіни; однією з причин цього є те, що дані, які надходять до екземпляра Fledge через ваш новий трубопровод, будуть відправлені до системи зберігання, а потім далі до північних пунктів призначення, змішані з даними з інших трубопроводів у вашій системі. Якщо ваш новий трубопровод є некоректним або генерує неякісні дані, ви опинитеся в ситуації, коли ці дані будуть надіслані до існуючих висхідних систем.
Якщо неможливо уникнути використання одного і того ж екземпляра, існують методи, які можна використати для зменшення ризику, а саме: використання фільтра активів для блокування даних з вашого нового південного трубопроводу, що надходять до існуючих північних трубопроводів, а потім надсилаються до ваших систем видобутку. Для цього потрібно просто вставити фільтр на початку кожного з існуючих північних трубопроводів і налаштувати його так, щоб він виключав названі активи, які будуть поглинуті вашим новим, експериментальним трубопроводом. Це дозволить даним з існуючого південного трубопроводу продовжувати надходити до висхідних систем, але не дозволить вашим новим даним надходити до цих систем.
З таким підходом все ще існують ризики, пов'язані з тим, що новий сервіс може видобувати активи з іншою назвою, ніж ви очікували, або може видобувати більше активів, ніж ви очікували. Дані також надсилаються до сервісу сповіщень з вашого нового трубопроводу, що може вплинути на роботу цьго сервісу, хоча це менш імовірно, ніж надсилання неправильних або небажаних даних на північ. Існує також обмеження, що ваші нові дані будуть вилучені з буфера і не зможуть бути надіслані до існуючих північних трубопроводів, якщо згодом ви вирішите, що дані є якісними. Дані з новими назвами активів з вашого нового трубопроводу будуть надсилатися тільки після того, як ви видалите фільтр |assetFilter| з тих північних трубопроводів, які надсилають дані до ваших видобувних систем.
Розробка нових північних трубопроводів є менш ризикованою, оскільки дані, які надходять зі сховища і призначені для вашого нового трубопроводу до видобувних систем, фактично дублюються, коли вони залишають систему зберігання. Основний ризик полягає в тому, що ця нова послуга вважатиметься такою, ніби дані були надіслані до системи зберігання, і це може призвести до того, що ваші дані стануть придатними для використання системою очищення раніше, ніж це було б у іншому випадку. Якщо ви хочете запобігти цьому, ви можете оновити конфігурацію очищення, щоб наполягати на надсиланні даних на всі північні канали, перш ніж вони вважатимуться надісланими для цілей системи очищення. У більшості випадків це запобіжний захід, який можна проігнорувати, однак, якщо ви налаштували систему Fledge на агресивне очищення даних, вам варто це врахувати.
Інкрементна розробка
Механізм трубопроводу Fledge розроблений для модульної розробки вимог до обробки даних вашого додатку. трубопровод будується з набору невеликих цільових фільтрів, кожен з яких виконує невеликий інкрементний процес обробки даних. При створенні трубопроводів, особливо при використанні фільтрів, які дозволяють застосовувати скрипти до даних, слід враховувати цей підхід і не створювати існуючу функціональність, яку можна імпортувати, застосувавши існуючий фільтр до трубопроводу. Замість цього використовуйте існуючий фільтр і додайте більше кроків до трубопроводу, оскільки середовище Fledge розроблено таким чином, щоб забезпечити мінімальні накладні витрати при об'єднанні фільтрів у трубопровод. Крім того, розробник трубопроводу може використовувати вже існуючі та протестовані фільтри, таким чином зменшуючи витрати на розробку та тестування нової функціональності, яка не є необхідною.
Такий підхід також може бути прийнятий в процесі побудови трубопроводу, особливо якщо ви використовуєте |assetFilter| для блокування подальшого просування даних через систему Fledge після їх буферизації в шарі зберігання. Просто додайте ваш південний сервіс, запустіть його і подивіться на дані, які буферизуються з цього сервісу. Тепер ви можете додати до трубопроводу ще один фільтр і поспостерігати, як він змінює дані, що буферизуються. Оскільки ви заблокували передачу даних далі у вашій системі, ці дані зникнуть в рамках звичайного процесу очищення і не потраплять у висхідні системи на північ від Fledge.
Якщо ви розробляєте на автономному екземплярі Fledge, без наявних північних сервісів, і ви все одно хочете, щоб ваші експериментальні дані зникли, цього можна досягти за допомогою процесу очищення. Просто налаштуйте процес очищення на часте видалення даних і встановіть процес на видалення невідправлених даних. Це означатиме, що дані залишатимуться у буфері, щоб ви могли їх переглянути протягом короткого часу, перш ніж їх буде видалено з буфера. Просто налаштуйте інтервал очищення так, щоб у вас було достатньо часу для перегляду даних у буфері. Якщо всі експериментальні дані було очищено до того, як ви запустите систему, у вас не виникне проблем з надсиланням експериментальних даних наверх.
Звичайно, не забудьте переналаштувати процес очищення, щоб він більше відповідав тривалості, протягом якої ви бажаєте зберігати дані, і вимкнути очищення невідправлених даних, якщо ви не бажаєте втратити дані, які не можуть бути відправлені протягом періоду часу, що перевищує інтервал очищення.
Налаштування більш агресивної системи очищення з вилученням невідправлених даних, ймовірно, не є тим, що ви хотіли б робити в існуючій системі з живими трубопроводами даних, і не повинно використовуватися як метод для розробки нових трубопроводів у такій системі.
Альтернативним підходом для видалення даних із системи є увімкнення функції Features of Developer у користувацькому інтерфейсі Fledge. Це можна зробити, вибравши сторінку Settings в меню ліворуч і натиснувши опцію внизу екрана.
Серед додаткових функцій, які можна отримати, вибравши Features of Developer, буде можливість вручну очищати дані зі сховища даних Fledge. Це очищення на вимогу може бути застосовано як до одного активу, так і до всіх актив�ів у сховищі даних. Доступ до операцій ручного очищення здійснюється через пункт Assets & Readings в меню Fledge. Коли увімкнено Features of Developer, з'являться кілька нових піктограм, по одній для кожного активу і одна, яка впливає на всі активи.

Ці іконки нагадують гумки і розташовані в кожному рядку активів, а також у верхньому правому куті поруч з іконкою довідки. Натискання на піктограму гумки в кожному з рядків очистить дані тільки для цього активу, залишаючи інші активи недоторканими. Натискання на піктограму у верхньому правому куті призведе до очищення всіх активів, які наразі знаходяться у сховищі даних.
В обох випадках буде показано діалогове вікно підтвердження, щоб запобігти випадковому використанню. Якщо ви вирішите продовжити, вибрані дані в буфері Fledge, або всі, або певний актив, буде видалено. Не існує способу скасувати цю операцію або відновити дані після того, як вони були видалені.
Інший наслідок, який може виникнути при розробці нових трубопроводів, полягає в тому, що в процесі розр�обки створюються активи, які не потрібні в готовому трубопроводі. Однак актив залишається пов'язаним з послугою, а назва активу і кількість отриманих показань буде відображатися на сторінці South Services в інтерфейсі користувача.

Ви можете знецінити зв'язок між послугою та назвою активу, використовуючи можливості інтерфейсу користувача для розробників. Для цього ви повинні спочатку увімкнути Features of Developer на сторінці налаштувань користувацького інтерфейсу. Тепер при перегляді сторінки South Services ви побачите значок гумки поруч з кожним активом, перерахованим для послуги.

Якщо ви натиснете на цю іконку, вам буде запропоновано розірвати зв'язок між активом і послугою. Якщо ви виберете Yes, зв'язок буде розірвано, і актив більше не відображатиметься поруч із сервісом.
Видалення зв'язку не призведе до видалення статистики для активу, просто буде видалено зв'язок з послугою, а отже, він не буде відображатися поруч з послугою.
Якщо зв'язок з активом вилучено для активу, який все ще використовується, його буде автоматично відновлено наступного разу, коли для цього активу буде отримано дані. Оскільки статистика не була видалена, коли зв'язок було знищено, попередні показники все ще будуть включені до статистики, коли зв'язок буде відновлено.
Ці Features of Developer призначені для використання при розробці трубопроводів у Fledge, функціональність не є чимось, що слід використовувати у звичайній роботі, і функції розробника слід вимкнути, коли трубопроводи не розробляються.
Пісочниця для Північної Системи
Розробка північних трубопроводів по частинах може бути більш проблематичною, оскільки ви навряд чи захочете вводити погано відформатовані дані у свої видобувні системи. Один з підходів до вирішення цієї проблеми полягає в тому, щоб мати якусь "жертовну" північну систему, яку ви можете використовувати для розробки трубопроводу і визначення того, чи виконується на ньому необхідний процес. У цьому випадку неважливо, якщо ця система буде забруднена даними не в тій формі, яка вам потрібна. В ідеалі, ви повинні використовувати систему того ж типу для розробки, а потім переключитися на виробничу систему, коли ви переконаєтеся, що ваш трубопровод працює правильно.
Якщо з якихось причин це неможливо, другим варіантом буде використання іншого екземпляра Fledge в якості тестової північної системи. Замість того, щоб налаштовувати північний плагін, який ви хочете використовувати, ви можете встановити північний HTTP-плагін і підключити його до другого екземпляра Fledge з запущеним HTTP-плагіном. Ваші дані будуть надіслані на новий екземпляр Fledge, де ви зможете переглянути дані, щоб побачити, що було надіслано першим екземпляром Fledge. Потім ви створюєте північний трубопровод на цьому першому екземплярі Fledge так само, як ви це робили з південним трубопроводом. Після того, як ви переконаєтеся, вам потрібно буде ретельно відтворити ваш північний трубопровод на основі правильного північного плагіна, і ви можете видалити ваш експериментальний північний трубопровод і знищити ваш жертовний екземпляр Fledge, який ви використовували для буферизації і перегляду даних.
Специфічні міркування щодо OMF
Деякі північні плагіни створюють специфічні проблеми для підходу інкрементальної розробки, оскільки зміна формату даних, які до них надсилаються, може спричинити внутрішні проблеми. Одним з таких плагінів є плагін OMF, який використовується для надсилання даних до PI-сервера Aveva.
Проблема з PI-сервером полягає в тому, що він призначений для зберігання даних у фіксованих форматах, тому наявність даних, які не мають узгодженого типу, тобто складаються з набору атрибутів, може спричинити проблеми. У PI-сервері кожен новий тип даних стає новим тегом, це не є проблемою, якщо ви бажаєте використовувати гнучкі імена тегів. Однак, якщо ви вимагаєте, щоб у PI-сервері використовувалися фіксовані імена тегів, використовуючи фільтр OMFhints, це може стати проблемою для інкрементального розвитку вашого трубопроводу. Зміна властивостей тегу призведе до того, що для нього буде потрібно нове ім'я.
Найпростіший підхід полягає у тому, щоб виконати всю початкову розробку без фіксованої назви, а потім виконати зіставлення назв на завершальному етапі розробки трубопроводу. Хоча це не ідеальний варіант, він дає відносно простий підхід до вирішення проблеми.
Якщо вам згодом знадобиться повторно використовувати імена тегів з різними типами, необхідно буде очистити визначення типів з PI Server, видаливши шаблони елементів, самі елементи і кеш. Після цього потрібно перезапустити PI Web API, видалити і створити заново плагін Fledge north.
Вивчення даних
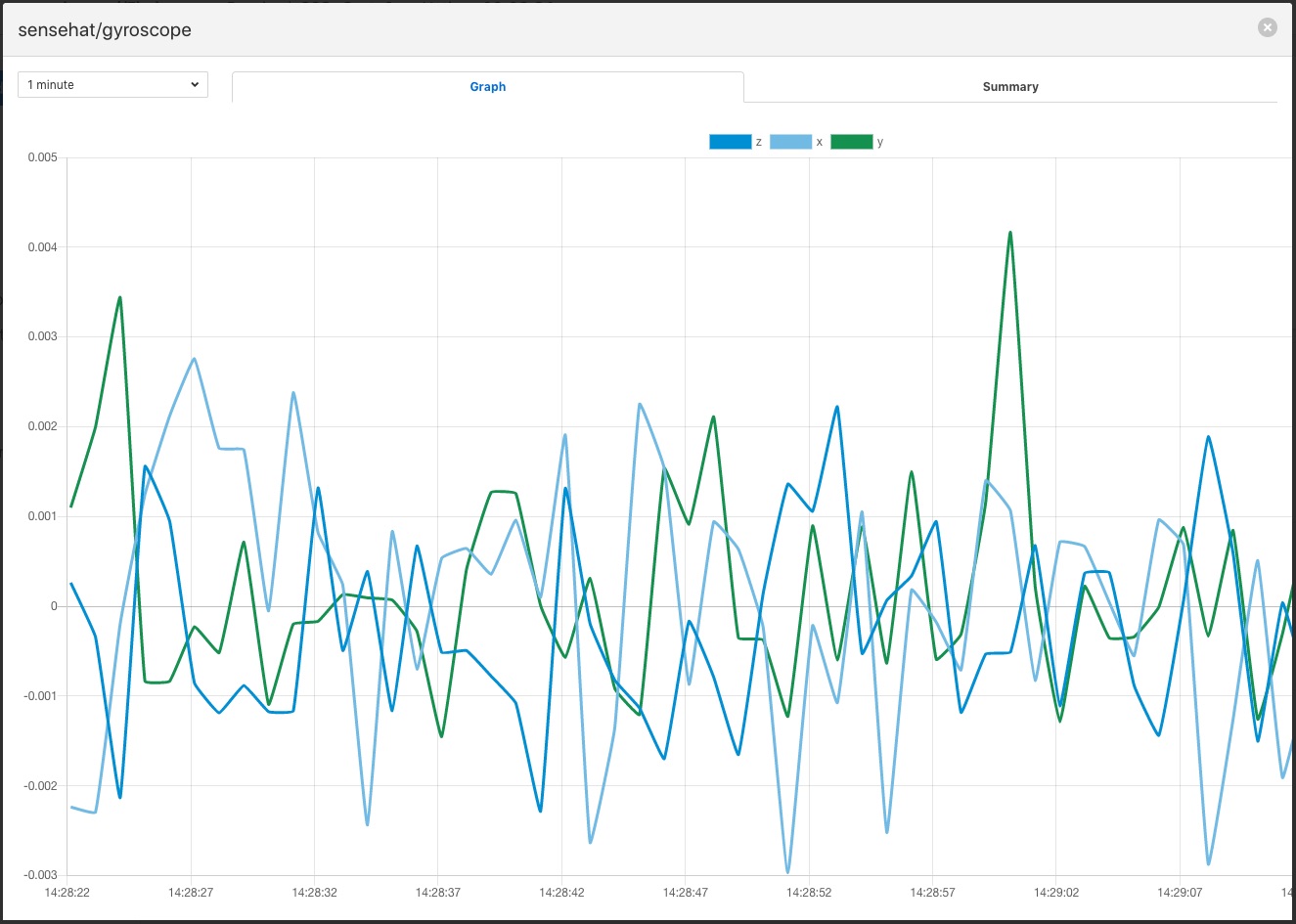
Найпростіший спосіб перевірити дані, які ви отримали через новий південний трубопровод, - це скористатися графічним інтерфейсом Fledge для перевірки даних, які наразі знаходяться в буфері. Ви можете переглянути дані або за допомогою графічної функції на сторінці Активи та показання, яка покаже дані часових рядів.
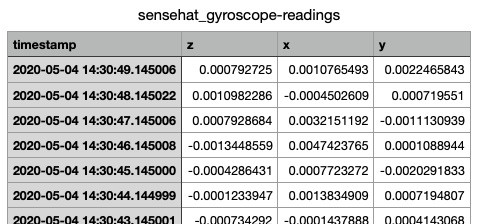
Якщо у вас є дані, які за своєю природою не є часовими рядами, наприклад, рядки, ви можете скористатися табличним відображенням, щоб показати дані, які не є часовими рядами, зображення, якщо такі є, або завантажити дані в електронну таблицю. Таке подання не міститиме жодних зображень у показаннях.
Вивчення журналів
Важливо переглядати логи для вашого сервісу під час побудови трубопроводу, це пов'язано з тим, що екземпляри Fledge повинні працювати як автоматизовані сервіси, а отже, будь-які помилки або попередження, що генеруються, записуються до журналів, а не в інтерактивний сеанс користувача. Проте, інтерфейс користувача Fledge надає ряд механізмів для перегляду даних журналу та їх фільтрації за певними джерелами. Ви можете переглянути журнал з пункту "System" в меню "Log", а потім відфільтрувати джерело до певної півден�ної або північного сервісу.
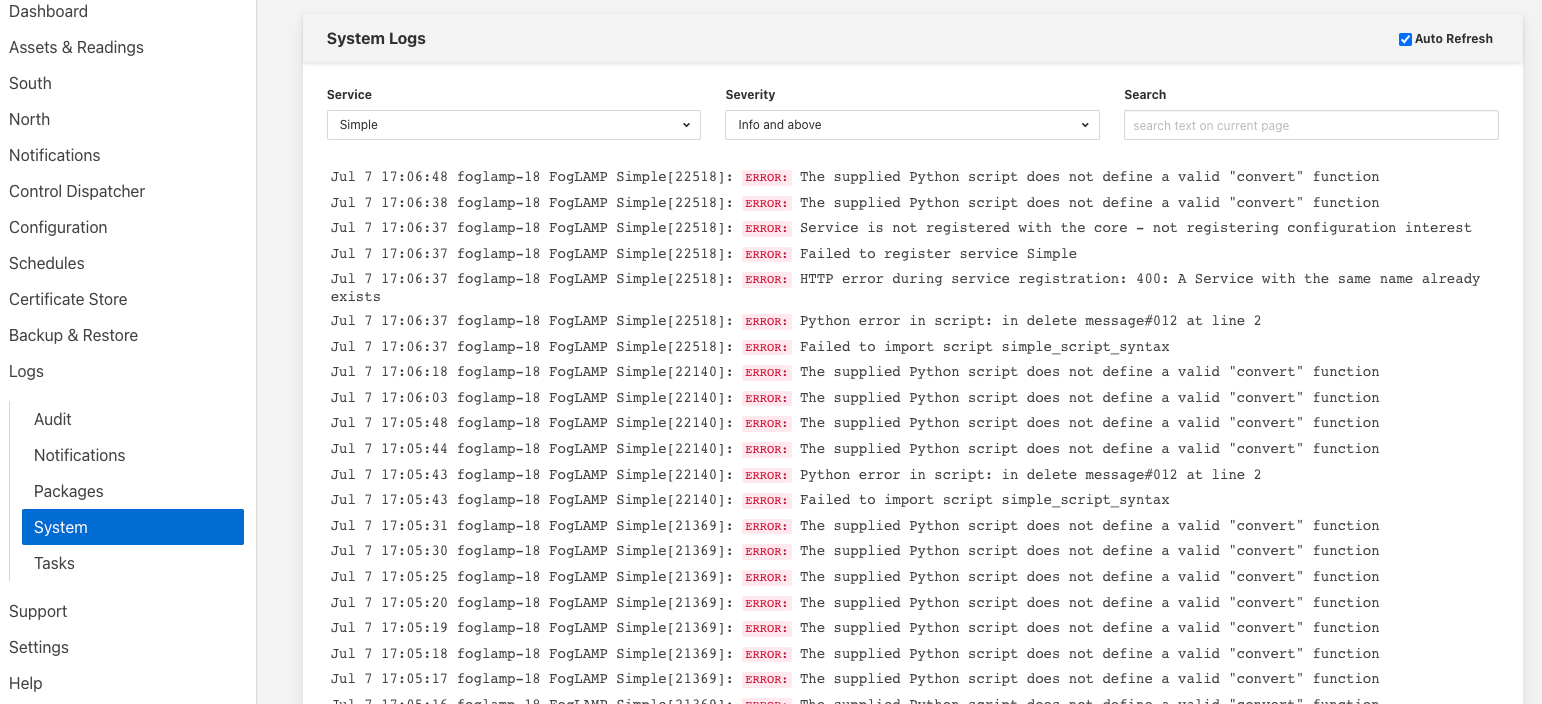
Крім того, якщо ви відкриваєте сторінку конфігурації північної або південної частини вашого сервісу, ви побачите іконку в нижньому лівому кутку екрана, яка виглядає як сторінка тексту із загнутим кутом. Просто натисніть на цю піктограму, і на екрані відобразиться сторінка журналу, яка буде автоматично відфільтрована для перегляду журналів тільки того сервісу, конфігурацію якої ви редагували раніше.

Журнал відображається спочатку з найновішим записом, а старіші записи показуються в міру просування вниз по сторінці. Ви можете перейти на наступну сторінку, щоб переглянути старіші записи журналу. Також можна переглянути різні ступені серйозності журналу: фатальні, помилки, попередження, інформаційні та налагоджувальні. За замовчуванням сервіс не буде записувати інформаційні та налагоджувальні повідомлення до журналу, але ви можете увімкнути ці рівні за допомогою додаткових параметрів конфігурації сервісу. Це призведе до того, що записи до журналу будуть записуватися, але перед тим, як ви зможете їх переглянути, ви повинні встановити відповідний рівень фільтрації суворості, і користувацький інтерфейс за замовчуванням відфільтрує інформаційні та налагоджувальні повідомлення.
Важливо, щоб після завершення сеансу налагодження ви повернули рівень журналювання до попереджень і вище, інакше це призведе до запису надмірної кількості записів до системного журналу.
Також зауважте, що журнали записуються до підсистеми журналювання базової версії Linux, або до syslog, або до механізму повідомлень, залежно від вашого дистрибутива Linux. Це означає, що ці файли журналів будуть автоматично ротируватися механізмами операційної системи. Це означає, що за звичайних обставин система не буде заповнювати підсистему зберігання даних. Старіші файли журналів зберігатимуться протягом короткого часу, але будуть автоматично видалені через кілька днів. Це слід мати на увазі, якщо в журналі є інформація, яку ви хочете зберегти. Крім того, користувацький інтерфейс дозволить вам переглядати дані лише в останньому файлі журналу.
Також можна налаштувати механізм syslog для запису файлів журналу у нестандартні файли або на віддалені машини. Механізми Fledge для перегляду системних журналів вимагають використання стандартних імен для файлів журналів.
Увімкнення та вимкнення фільтрів
Слід зазначити, що кожен фільтр має індивідуальне керування увімкненням, це має ту перевагу, що його легко тимчасово вилучити з трубопроводу на етапі розробки. Однак це має і зворотній бік - легко забути увімкнути фільтр у трубопроводі або випадково додати фільтр у вимкненому стані.
Плагіни для написання скриптів
Якщо не існує плагіна, який робить те, що потрібно, або у фільтрі, або в південних плагінах, де корисне навантаження протоколу сильно варіюється, таких як загальні плагіни REST або MQTT, Fledge пропонує можливість використання мови скриптів, щоб розширити набір готових плагінів.
Це здійснюється за допомогою мови скриптів Python, Fledge підтримує як Python 3, так і Python 2, однак рекомендується використову�вати варіант Python 3, python35 за уподобанням. Підтримка Python дозволяє використовувати зовнішні бібліотеки для розширення базової функціональності Python, однак наразі слід зазначити, що бібліотеки Python мають бути встановлені вручну на хост-машину Fledge.
Посібник зі створення скриптів
Користувач має повний спектр функціональних можливостей Python, доступних йому в коді скриптів, які він надає цьому фільтру, однак слід бути обережним, оскільки можна негативно вплинути на функціональність і продуктивність системи Fledge, зловживаючи можливостями Python на шкоду власне функціям Fledge.
Загальні принципи, що лежать в основі всіх фільтрів Fledge, застосовуються до скриптів, що входять до складу цих фільтрів;
- Не дублюйте функціонал існуючих фільтрів.
- Робіть операції невеликими і цілеспрямованими. Краще мати кілька фільтрів, кожен з яких має певну мету, ніж створювати великі, складні скрипти на Python.
- Не буферизуйте великі об'єми даних, це вплине на використання сервісу, а також сповільнить роботу трубопроводу даних.
Iмпортування пакетів Python
Користувач може імпортувати будь-які пакети у скрипт Python, включаючи пакети типу numpy та інші, які обмежуються одним екземпляром у інтерпретаторі Python.
Не імпортуйте пакети, які ви не використовуєте або які вам не потрібні. Це створює додаткові накладні витрати на фільтр і може вплинути на продуктивність Fledge. Імпортуйте лише ті пакети, які вам дійсно потрібні.
У Python не передбачено механізму видалення пакетів, які було імпортовано раніше, тому якщо ви імпортуєте пакет у свій скрипт, а потім оновлюєте скрипт, щоб більше не імпортувати пакет, пакет все одно залишиться у пам'яті з попереднього імпорту. Це відбувається тому, що ми перезавантажуємо оновлені скрипти без завершення роботи інтерпретатора Python. Це частина спільного використання інтерпретатора, необхідна для того, щоб дозволити використання таких пакетів, як numpy і scipy. Це може призвести до оманливої поведінки, оскільки при перезапуску сервісу пакет не буде завантажено і скрипт може зламатися, оскільки він все ще використовує пакет.
Якщо ви видалите імпорт пакетів зі свого скрипта і хочете бути повністю впевненими, що скрипт працюватиме без нього, вам необхідно перезапустити сервіс, в якому ви використовуєте плагін. Це можна зробити, вимкнувши, а потім знову ввімкнувши сервіс.
Одна з функцій Developer Features користувацького інтерфейсу Fledge дозволяє керувати встановленими пакетами Python з інтерфейсу користувача. Ця функція вмикається за допомогою перемикача Features of Developer на сторінці Settings і додає новий пункт меню під назвою Developer. Перехід на цю сторінку надасть можливість керувати пакетами
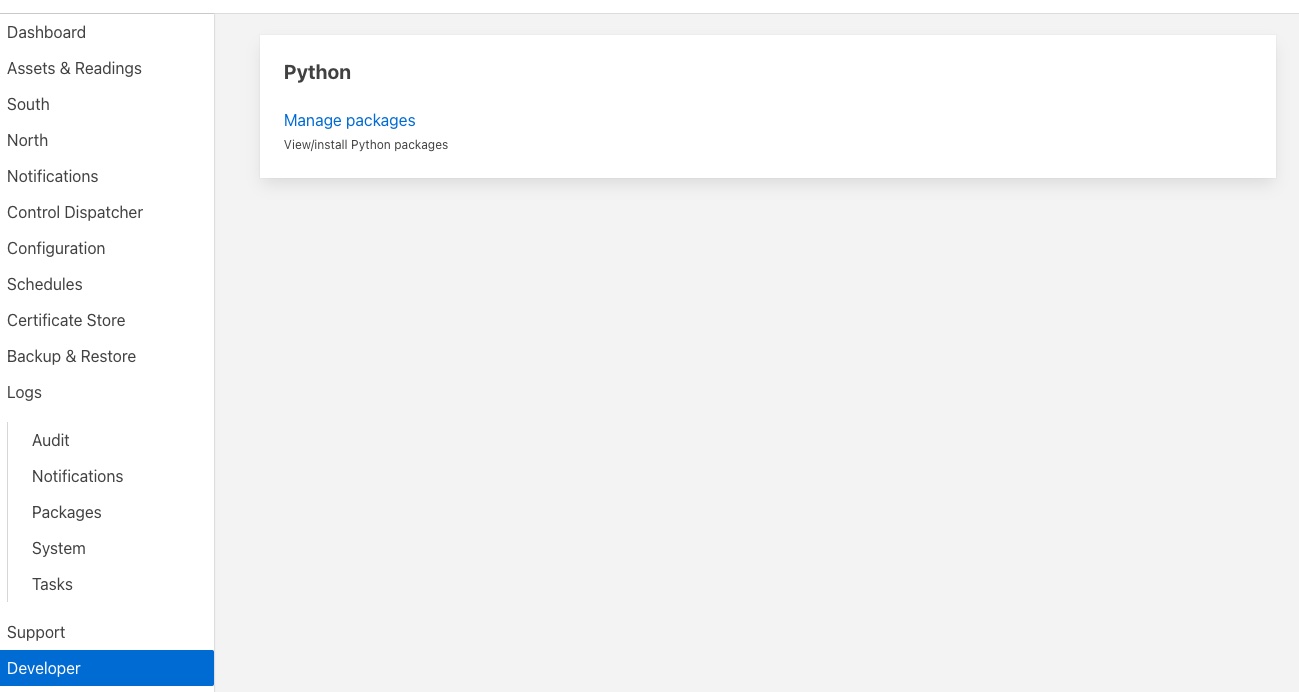
Натиснувши на посилання Manage packages, ви побачите поточний набір пакетів Python, встановлених на комп'ютері.
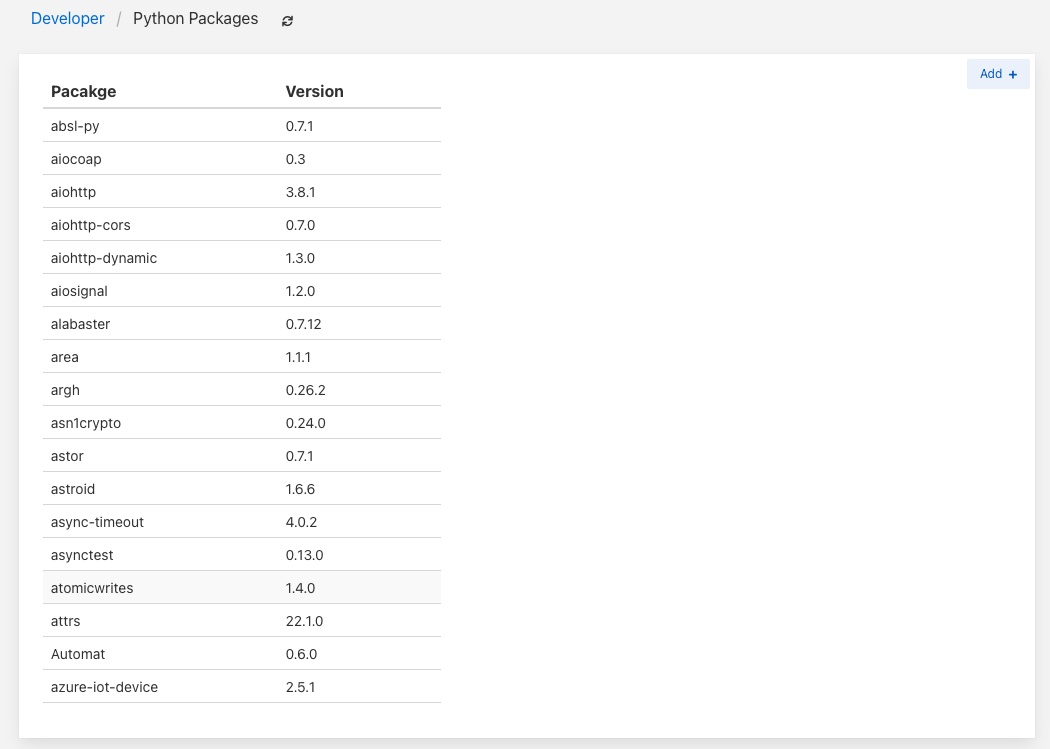
Щоб додати новий пакет, натисніть на посилання Add + у верхньому правому куті. На екрані з'явиться вікно, на якому ви зможете ввести дані пакета Python для встановлення.
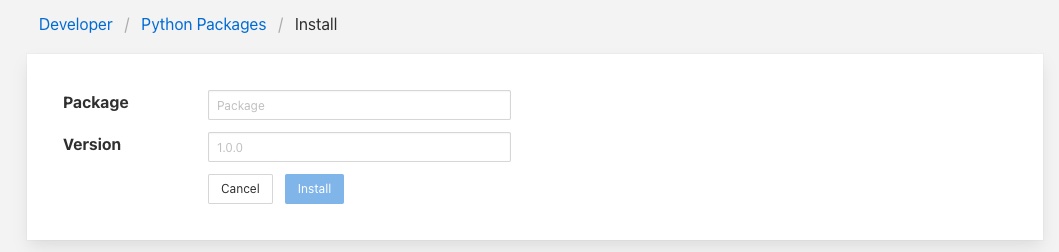
Введіть назву пакету і необов'язкову версію пакету, а потім натисніть кнопку Install, щоб встановити новий пакет через pip3.
Використання глобальних змінних
Ви можете використовувати глобальні змінні у вашому скрипті, і ці глобальні змінні зберігатимуть своє значення між викликами функції обробки. Ви можете використовувати глобальні змінні як метод збереження інформації між виконаннями і виконувати такі операції, як аналіз трендів на основі даних, отриманих під час попередніх викликів функції фільтрації.
Весь код на Python в межах одного сервісу використовує один і той самий інтерпретатор Python, а отже, вони також мають од�наковий набір глобальних змінних. Це означає, що ви повинні бути обережними з іменами глобальних змінних, а також, якщо вам потрібно мати декілька екземплярів одного і того ж фільтра в одному трубопроводі, ви повинні знати, що глобальні змінні будуть спільними для них. Якщо ваш фільтр використовує глобальні змінні, зазвичай не рекомендується мати декілька їхніх екземплярів в одному трубопроводі.
Є спокуса використовувати спільний доступ до глобальних змінних як метод обміну інформацією між фільтрами, але це не рекомендується і не повинно використовуватися. На це є кілька причин
Це забезпечує зв'язок даних між фільтрами, кожен фільтр повинен бути незалежним від іншого фільтра. Один з фільтрів, що мають спільні глобальні змінні, може бути вимкнений користувачем з неочікуваними наслідками.
- Порядок фільтрів може бути змінено, в результаті чого дані, які очікуються наступним фільтром у ланцюжку, будуть недоступні. Проміжні фільтри можуть додавати або видаляти показники, в результаті чого дані в глобальних змінних не будуть посилатися на ті самі показники або набір показників, на які в�они мали б посилатися.
Якщо ви хочете, щоб один фільтр передав дані до наступного фільтра в трубопроводі, це найкраще зробити, додавши дані до показань як додаткову точку даних. Ця точка даних потім може бути видалена наступним фільтром. Прикладом цього є те, як Fledge додає OMFhints до показань, які обробляються і видаляються північним плагіном OMF.
Наприклад, припустімо, що ми обчислили деяку дельту значення, яку хочемо передати до пізнішого фільтра, ми можемо додати її як точку даних до нашого читання, яку назвемо _hintDelta.
def myPython(readings):
for elem in list(readings):
reading = elem['readings']
...
reading['_hintDelta'] = delta
...
return readings
Це набагато краще, ніж використання глобального, оскільки він прив'язується до читання, на яке посилається, і залишається прив'язаним до цього читання, доки його не буде вилучено. Це також означає, що вона не залежить від кількості зчитувань, які обробляються за один виклик, і є стійкою до додавання або вилучення зчитувань з потоку.
Назва, вибрана для цієї точки даних у наведеному вище прикладі, не має значення, однак, рекомендується вибирати назву, яка навряд чи зустрінеться в даних зазвичай і відображає використання або значення даних.
Операції файлового вводу-виводу
Можна використовувати операції з файлами у функції фільтрації Python, однак це не рекомендується для промислового використання з наступних причин;
- трубопроводи можуть бути переміщені на інші хости, де файли можуть бути недоступні.
- Дозволи можуть змінюватися в залежності від того, як розгортаються системи Fledge в різних скриптах.
- Периферійні пристрої також можуть не мати великого високопродуктивного сховища, що може призвести до проблем з продуктивністю Fledge або збоїв через брак місця.
- Fledge розроблений для управління виключно через API Fledge і додатки, які використовують цей інтерфейс. У цьому API немає можливості керувати довільними файлами у файловій системі.
Зазвичай під час розробки скриптів використовують файли для запису інформації, щоб полегшити розробку та налагодження, однак після запуску фільтра у виробництво це слід вилучити разом з імпортом пакетів, необхідних для виконання файлового вводу-виводу.
Потоки у Python
Заманливо використовувати потоки в Python для виконання фонової активності або для паралельної обробки наборів даних, однак існує проблема з потоками в Python - Глобальне блокування інтерпретатора Python або GIL (Python Global Interpreter Lock). GIL запобігає одночасному виконанню двох операторів Python в одному інтерпретаторі двома потоками. Оскільки ми використовуємо один інтерпретатор для всього Python-коду, що виконується в кожному сервісі Fledge, якщо створюється потік Python, який виконує в ньому роботу, що інтенсивно завантажує процесор, ми блокуємо виконання всього іншого Python-коду в цьому сервісі Fledge.
Тому ми уникаємо використання потоків Python у Fledge для виконання завдань, що вимагають багато процесорних активів, і використовуємо потоки Python лише для виконання завдань, що вимагають інтенсивного вводу-виводу, використовуючи механізм асинхронності Python 3.5.3 або новішої версії. У старих версіях Fledge ми використовували декілька інтерпретаторів, по одному на фільтр, щоб обійти цю проблему, однак це мало побічний ефект, що ряд популярних пакетів Python, таких як numpy, pandas і scipy, не могли бути використані, оскільки вони не можуть підтримувати декілька інтерпретаторів в одному адресному просторі. Було вирішено, що потреба у використанні цих пакетів була більшою, ніж потреба у підтримці декількох інтерпретаторів, і тому ми маємо один інтерпретатор на сервіс, щоб дозволити використання цих пакетів.
Взаємодія із зовнішніми системами
У фільтрі слід уникати взаємодії із зовнішніми системами, використовуючи мережеві з'єднання або будь-яку форму блокування зв'язку. Будь-яка операція блокування призведе до блокування даних у трубопроводі і ризикує або накопиченням великих черг даних у випадку асинхронних плагінів півдня, або пропуском даних у випадку опитуваних плагінів.
Помилки написання скриптів
кщо в плагіні або скрипті Python виникає помилка, включаючи помилки кодування скрипта і виключення Python, деталі будуть занесені до журналу помилок, і дані не будуть передаватися через трубопровод до наступного фільтра або до сервісу зберігання.
Отримані попередження також будуть занесені до журналу помилок, але не призведуть до припинення потоку даних через трубопровод.
Дивиться AccessingLogs докладніше про те, як отримати доступ до системних журналів.